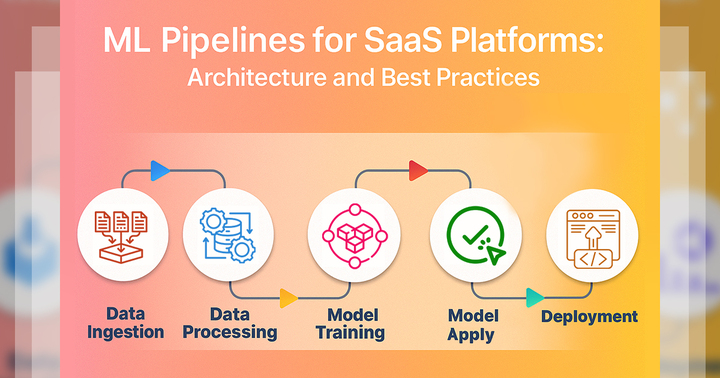
Learning about machine learning is an exciting journey that goes far beyond just reading technical terms or watching a few demos—it’s about understanding how computers can learn from data and make decisions that improve over time. Whether you’re curious about how Netflix suggests your favorite shows or how self-driving cars make split-second decisions, machine learning is at the heart of it all. And now, you’re about to explore how this powerful technology really works.
But how do you go from a curious beginner to someone who can build a real machine learning model? That’s where this guide comes in. It walks you through the entire learning process—from grasping simple concepts to writing your first lines of code. You’ll explore key algorithms, understand how models are trained and tested, and discover how real-world problems are solved using data.
Whether your goal is to explore a new career path, boost your coding skills, or just satisfy your curiosity, this guide will give you the confidence and clarity you need to get started. Ready to dive in and unlock the power of machine learning? Let’s begin your journey!
1. What Is Machine Learning?
- Machine learning is a part of artificial intelligence that lets computers learn from data instead of being told exactly what to do. You give the computer a lot of examples, and it finds patterns on its own. Over time, it gets better at making decisions or predictions without needing new instructions. Think of it like teaching a friend by showing, not telling. You don’t write all the rules—the computer figures them out by learning from the information you give it.
1.1 Key Characteristics of Machine Learning:
a. Data-Driven: Relies on datasets (e.g., images, text, numbers) to “learn.”
- Machine learning depends on data to work. You give it examples like images, texts, or numbers, and it learns patterns from them. You don’t have to tell it exactly what to do. Instead, it figures things out by studying the information you provide. The more data it has, the smarter it gets. So, if you want it to perform well, you need to give it plenty of good examples to help it learn effectively.
b. Adaptive: Models adjust their behavior as they process new data.
- Machine learning is adaptive, which means it can change and improve over time. When you give it new data, it adjusts how it works to get better results. Just like you get better with practice, the model learns from its mistakes and updates itself. You don’t need to reprogram it—it keeps learning from what you show it. This makes it very useful when things are always changing, like trends or habits, because it can adapt quickly.
c. Predictive: Used to forecast outcomes or classify information.
- Machine learning is predictive, so it can make smart guesses about future events. When it sees a new problem, it uses what it has already learned from past data to make a prediction or decision. You might see this in action when it guesses your next word while typing or suggests music you might like. It’s not magic—it just uses patterns it already knows to make forecasts or classify things accurately based on what you’ve done before.
d. Example – Netflix:
- When you watch shows on Netflix, the system remembers what you like. It uses machine learning to look at your watch history, find patterns, and suggest similar shows or movies. You don’t tell it what to recommend—it learns your preferences by itself. The more you watch, the better it gets at knowing your taste. This is a perfect example of predictive, data-driven, and adaptive machine learning in action, helping you discover new things without even asking.
2 Types of Machine Learning
2.1 Supervised Learning
a. How It Works:
- In supervised learning, you train a model using labeled data. That means you give it examples where the input and correct output are already known. For example, if you want to teach it to recognize cats in photos, you give it pictures labeled “cat” or “not cat.” The model learns by comparing its guesses to the correct answers. Over time, it figures out how to make better predictions. You’re basically showing it examples and teaching it by saying, “This is right, this is wrong.”
b. Use Cases
- You can use supervised learning in many real-life situations. For example, it helps email services detect spam by learning what spam emails usually look like. It can also be used in weather forecasting, where it studies past weather data to predict things like temperature or rain. If you give it the right kind of labeled data, it can learn to make very accurate guesses. You use it anytime you want the model to learn from examples with clear answers.
c. Example Algorithm: Linear Regression (predicting house prices)
- A common algorithm in supervised learning is Linear Regression. It helps make predictions about something based on numbers. For example, if you want to guess the price of a house, you can look at things like its size, location, and number of rooms. You give the model data about many houses and their actual prices. It learns the relationship between the features and the price. Then, when you give it a new house, it predicts how much it might cost.
2.2 Unsupervised Learning
a. How It Works:
- In unsupervised learning, the model looks at unlabeled data, which means you don’t tell it the correct answers. You just give it a bunch of data, and it tries to find patterns or groups on its own. It’s like handing someone a pile of puzzle pieces without a picture—they figure out what fits where. You don’t teach the model by saying, “This is right or wrong.” Instead, it explores the data and finds interesting structures or similarities by itself.
b. Use Cases:
- You can use unsupervised learning in real life when you don’t have labeled data. For example, businesses use it for customer segmentation—it helps group people based on their shopping habits, even if you haven’t told the model what each group means. It’s also great for anomaly detection, like spotting strange behavior in a bank account that might mean fraud. The model looks for what’s “normal,” and then flags things that don’t match. You use it to discover hidden patterns.
c. Example Algorithm – K-Means Clustering:
- A popular unsupervised learning algorithm is K-Means Clustering. It takes a bunch of data points and groups them based on how similar they are. Imagine you have data on students’ test scores and study hours. K-Means can group students into clusters like “high scorers” or “needs improvement,” even if you didn’t label them. You just tell it how many clusters you want, and it organizes the data into those groups. It’s useful when you want to see how things naturally fit together.
2.3 Reinforcement Learning
a. How It Works:
- In reinforcement learning, a model learns through trial and error. You don’t give it answers—instead, it explores and tries different actions. When it does something right, it earns a reward. When a mistake is made, it gets a lower score or a penalty. Over time, it learns which actions lead to better results. It’s like when you play a video game—you learn what works by trying, failing, and improving. The model becomes smarter by learning from its experiences and aiming for more rewards
b. Use Cases:
- You use reinforcement learning in places where decisions happen step-by-step. One example is in robotics, where a robot learns to walk or pick up objects by trying and learning from what works. Another big use is in game-playing AI, like AlphaGo, which beat world champions in the game of Go. These models learn strategies by playing millions of games and getting rewards for winning. It’s helpful when you want the system to learn complex behavior over time through practice.
3. Essential Machine Learning Algorithms for Beginners
a. Linear Regression – Supervised – Predicting Numerical Values:
- Linear Regression helps you predict numbers based on other values. For example, if you want to guess the price of a house, you can use features like its size and number of rooms. This algorithm draws a straight line that best fits the data points. You use it when your goal is to predict a continuous number, not a category. It’s one of the simplest forms of supervised learning, and it learns from data that already has correct answers to find trends and relationships.
b. Decision Trees – Supervised – Classification and Regression:
- A Decision Tree is like a flowchart that helps you make choices by asking simple yes or no questions. It’s used in supervised learning for both classification (picking a category) and regression (predicting numbers). You start at the top and follow the branches based on your answers until you reach a final decision. It’s easy to understand and works well when you want to figure out what causes certain results. You train it with labeled data so it knows which paths lead to the correct outcomes.
c. K-Nearest Neighbors – Supervised – Pattern Recognition:
- K-Nearest Neighbors (K-NN) helps the model recognize patterns by looking at the closest examples. When you give it something new, it checks which of its neighbors (similar past examples) are closest, then guesses the answer based on what most neighbors are. It’s great for classification problems, like figuring out if a fruit is an apple or an orange based on color and shape. You use supervised learning with K-NN, meaning you train it with labeled data. It’s simple but powerful for spotting similarities.
d. Neural Networks – Deep Learning – Complex Tasks (e.g., Image Recognition):
- Neural Networks are inspired by how your brain works. They have layers of tiny units called neurons that process information. You use them in deep learning, which is a more advanced part of machine learning. They’re great for complex tasks like recognizing faces in photos or understanding spoken words. Neural networks learn by adjusting their internal connections each time they see new data. You give them lots of labeled examples, and over time, they learn to make very accurate predictions for difficult problems.
3.1 Deep Dive: Neural Networks
- Neural networks are models that copy how your brain works. They use layers of tiny units called neurons to take in data, understand it, and make decisions. Each layer passes information to the next, helping the model learn more complex things. You don’t need to program every step—it figures things out by learning from examples. Neural networks are perfect for big tasks like image recognition and language understanding, where you need a system that can handle lots of details at once.
a. Image classification (e.g., identifying tumors in X-rays)
- You can use neural networks to do image classification, which means recognizing what’s in a picture. For example, doctors use them to spot tumors in X-rays. You give the model lots of images labeled “tumor” or “no tumor,” and it learns the differences. Over time, it gets really good at finding those patterns in new images. It’s like giving the computer a kind of vision so it can help make faster, smarter diagnoses in healthcare.
b. Natural language processing (e.g., ChatGPT)
- Neural networks are also great at natural language processing, which means understanding and working with human language. That’s what tools like ChatGPT use to read your messages and reply in a way that makes sense. You teach the model by showing it tons of examples of how people talk or write. Then it learns grammar, word meaning, and even tone. So when you ask a question, it gives a smart, human-like response that feels natural and helpful.
4. Tools & Frameworks to Get Started
4.1 Python
- Python is the most popular programming language for machine learning. It’s easy to read and has powerful libraries like scikit-learn for basic ML and TensorFlow for deep learning. You can write simple code to build smart models without needing to be a coding expert. If you’re just starting out, Python is a great place to begin because it helps you focus on learning machine learning, not just coding rules.
4.2 Jupyter Notebooks
- Jupyter Notebooks give you a fun, interactive way to write and test your code. You can type Python code in small chunks, run it right away, and see the results. It’s perfect for experimentation because you can add notes, charts, and results in one place. This makes it easier to understand what’s happening step by step. You use Jupyter Notebooks to learn, test, and share your machine learning ideas clearly and easily.
4.3 Kaggle:
- Kaggle is a cool online platform where you can find real datasets, follow tutorials, and join competitions to practice your skills. You can try building ML models, learn from others, and even win prizes. It’s like a playground for learning machine learning by doing. You don’t need to worry about setup—just log in, code in your browser, and start exploring. It’s a great way to improve and see how other people solve real problems using ML.
4.4 Step-by-Step: Installing Python Libraries

- Through this command, you can install two important Python libraries: scikit-learn and pandas. You use scikit-learn to build and train machine learning models, and pandas to work with data in tables (like rows and columns). The word pip is a tool that helps you download and set up these packages, so you don’t have to do it manually. It makes getting started with ML super easy.
5. How to Build Your First ML Model (With Code Example)
Step 1: Import Libraries

- In this step 1, you import libraries from scikit-learn, which is a powerful machine learning tool in Python. First,
**load_iris**gives you a famous built-in dataset about flowers that you can use to practice. Then,**train_test_split**helps you split your data into two parts: one for training your model and one for testing it to see how well it works. Finally,**RandomForestClassifier**it is the actual machine learning model you’ll train—it learns by using many decision trees to make smart predictions. You import all these tools so you can build, train, and test your first real ML model in just a few steps, all using easy-to-understand code.
Step 2: Load and Split Data

- In this step 2, you’re using the load_iris() function to load a simple dataset about iris flowers, which includes data like petal size and flower type. This data gets stored in a variable called iris. Then, you use train_test_split() to break that data into two parts: X_train and y_train (for training the model) and X_test and y_test (for testing it). The test_size=0.2 means you’re using 80% of the data to teach the model and saving 20% to check how well it learns. You do this so your model doesn’t just memorize everything—it actually learns and can make smart predictions on new data it hasn’t seen before.
Step 3: Train the Model

- In this step 3, you’re creating a machine learning model by using RandomForestClassifier(), which builds a group of decision trees to make smart predictions. You save this model in a variable called model. Then, you use the fit() function to train the model using the training data you created earlier—X_train (the input data) and y_train (the correct answers). When you run **
model.fit()**, the model looks at all the examples, learns the patterns, and figures out how to guess the correct output. This is the step where your model actually learns, kind of like how you study with examples before a test, so you can answer questions later on your own.
Step 4: Evaluate Accuracy

Output:

- In this final step, you’re checking how accurate your model is by using the score() function. You give it X_test (the test data) and y_test (the correct answers), and it compares the model’s predictions to the real answers. The result is a number between 0 and 1 that tells you how well your model did—like a grade on a test. When you print
**model.score()**, you see the accuracy as a percentage. For example, 0.96 means your model got 96% of the answers right. This tells you the model has learned well and can make good predictions on new data. It’s how you measure the success of your machine learning project.
6. Common Challenges for Beginners
a. Poor-Quality Data:
- When working with data, you might face issues like duplicates or irrelevant features that mess up your model. To fix this, you need to clean your dataset by removing these errors. This process is called data cleaning, and it helps make sure your model gets the right information to learn from. By having good-quality data, your model will perform much better, avoiding mistakes and inaccurate predictions.
b. Overfitting:
- Overfitting happens when your model learns the training data too well, including the noise and random details, making it perform poorly on new data. To fix this, you can simplify your model, removing unnecessary complexity. You can also use cross-validation, where the model is trained on different parts of the data, helping it generalize better and avoid memorizing the training set. This improves its accuracy on unseen data.
c. Math Anxiety:
- It’s normal to feel overwhelmed by the math behind machine learning, like calculus. But don’t worry—focus on the practical coding side first. As you build models and see them in action, the math will start to make sense. Concepts like derivatives or integrals are easier to understand when you apply them to real problems. So, don’t stress too much about the math at first—just dive into the coding, and the math will click as you go!
7. The Future of Machine Learning in 2025
- In 2025, the future of machine learning looks exciting and full of new opportunities. You’ll see tools like AutoML that let you build models without deep coding skills. Quantum ML will help solve big problems faster than ever. Most importantly, you’ll learn how to create ethical AI—models that are fair and transparent. As someone starting out, you’ll have more tools, power, and responsibility to build smart systems that truly help people and shape the world.
7.1 AutoML
- It stands for Automated Machine Learning, and it helps you build models without needing to be an expert. Tools like Google’s AutoML do most of the hard work for you, like choosing the right model and tuning settings. You just provide the data, and AutoML figures out the best way to learn from it. This is great if you’re still learning, because it makes powerful machine learning more accessible and lets you focus on results instead of technical details.
7.2 Quantum ML
- Quantum ML mixes quantum computing with machine learning to solve problems much faster. Quantum computers use special particles to do complex math way quicker than regular computers. When you combine this with ML, you get smarter models that can process huge amounts of data at lightning speed. While it’s still new, in the future, Quantum ML could change the way we do things like weather forecasting, medical research, and more. It’s a next-level tech worth keeping an eye on.
7.3 Ethical AI
- Ethical AI means making sure your ML models are fair, honest, and transparent. Sometimes, models can accidentally learn biases from the data, leading to unfair or wrong results. To fix this, researchers are building frameworks to check how decisions are made and make sure models treat everyone equally. As someone learning ML, it’s important to understand that ethics matter—you want to build AI that helps people and respects their rights. Being responsible is just as important as being smart.
Conclusion
- Machine learning is far more than just algorithms and datasets—it’s about creating smart, adaptable systems that can make meaningful decisions, solve complex problems, and improve with experience. Throughout your learning journey, curiosity, hands-on practice, and a willingness to explore new ideas are key to mastering the fundamentals and unlocking the potential of ML. By understanding each concept—from data preprocessing to model evaluation—you’ll be equipped to take your first steps with confidence and purpose.
- Machine learning is a continuously evolving field. As new tools and techniques emerge, staying engaged and learning from real-world applications will help you grow along with the technology. With a strong grasp of the basics, you’re ready to explore more advanced topics, experiment with your own projects, and join the growing community of machine learning innovators. Let your journey begin—and watch your skills grow with every model you build.