In today’s cloud-first world, you must design systems that handle data continuously and at scale. Building real-time systems in 2025 is not just about picking a stream processing library; it is about thinking in streams at every layer, from client ingestion to distributed processing to production-grade deployment. The technical choices you make today determine how quickly you can iterate, how observable your system is, and how well it survives real-world incidents.
Event-driven architecture is the natural fit for this challenge. Instead of forcing batch thinking onto streaming problems, you treat events as first-class citizens and design pipelines that are resilient, testable, and observable. By combining durable processing engines with clear telemetry and repeatable deployment practices, you create a platform that supports rapid delivery while minimizing operational risk.
In this guide, you will walk through a practical roadmap that shows you, step by step, how to design, build, test, and operate a modern streaming platform ready for scale. We cover architecture decisions, platform choices, recommended tooling, deployment patterns including GitOps, and operational practices. We finish with a developer-friendly checklist you can follow, sprint by sprint, to turn the roadmap into actionable work.
1. The design mindset: streams first, modular always
- Before you choose any technology, start by focusing on your mindset. Imagine your project as a steady flow of data that moves naturally between different parts of your system. Try to make each part simple and modular, so it can work well on its own but still connect smoothly with the rest. When you think in streams first and modules always, you make it easier to handle growth, updates, and new ideas in the future with confidence and ease. Let’s discuss these two principles:
1.1 Streams first
a. Treating Every Change as an Event
- When you treat every change as an event, you make your system more responsive to real-time data. Each action, such as a user click or sensor reading, is recorded instantly and processed without delay. This helps you see what is happening right now instead of waiting for updates. It also makes it easier to react quickly, fix issues, or show live results. You learn to design systems that are dynamic, efficient, and always aware of new changes.
b. Power of Append-Only Events
- Using append-only events means you only add new records without changing old ones. This makes your system more transparent and trustworthy, as every event is saved in its original form. When you need to perform auditing or replays, you can easily track how data has changed over time. You gain a clear timeline of every action, which helps you detect problems or analyze trends. This method keeps your system consistent, reliable, and easy to debug.
c. Everyday Examples of Data Streams
- You deal with data streams all the time without noticing it. Every user action, such as liking a post, making an online payment, or sending a message, creates a new event. Even sensor readings, like temperature or speed data, flow as continuous streams. By modeling these as events, you can process them instantly to update dashboards or trigger alerts. This mindset helps you understand how streaming systems keep apps like social media and banking running smoothly in real time.
d. How Thinking in Streams Changes Design
- When you start thinking in streams, you no longer see data as static information stored in tables. Instead, you view it as a continuous flow of updates that never stops. This mindset changes how you design, store, and process data. You begin to build pipelines that handle information as it arrives, rather than waiting for batches. This makes your applications more responsive, scalable, and ready to deliver instant feedback to users in a fast-changing digital world.
e. Stream-Based vs Request-Based Systems
- In a traditional request-based system, data is only processed when a user sends a request. This can cause delays and reduce efficiency. In a stream-based system, information flows continuously, and updates happen automatically. You do not need to ask for data—it reaches you in real time. This makes your system more scalable, responsive, and ideal for modern use cases like live analytics or IoT. By choosing streams, you prepare for faster and smarter digital operations.
1.2 Modular ownership
a. Building a Reliable System through Separation
- When you separate ingestion, processing, serving, and UI layers, you make your system more reliable and easier to manage. Each part has its own purpose and can function without depending too much on others. If one layer faces an issue, the rest can still keep working properly. This helps you fix problems faster and maintain smooth performance. You create a structure that is organized, flexible, and capable of handling different tasks efficiently in any situation.
b. Improving Team Productivity with SLAs and Independence
- When every team has clear SLAs and independent deployments, work becomes faster and more efficient. Each team knows exactly what they are responsible for and can make updates without waiting for others. This reduces confusion and delays while increasing confidence in their results. You can test, release, and improve features on your own schedule. By managing your part independently, you contribute to a system that is productive, organized, and always moving forward.
c. Easier Updates and Debugging with Modular Design
- A modular design allows you to make updates or fix bugs in one part of the system without affecting the rest. Each module is like a building block that can be improved on its own. This helps you find problems faster and keep your system stable during changes. You do not need to stop everything just to fix one issue. This design makes your work simpler, your system safer, and your results more reliable and predictable.
d. Example of Scalability through Modular Ownership
- Imagine an online store that separates payment, inventory, order processing, and user interface modules. When traffic grows, you can scale only the parts that need more power, such as the payment or order modules. You do not have to rebuild everything. This approach saves time and resources while keeping performance steady. Through modular ownership, you can adapt quickly to user demand, making your system more scalable, efficient, and capable of handling future growth smoothly.
e. Applying the Modular Always Mindset
- As a developer, you can apply the modular always mindset by designing your app in clear, independent sections. Think of each part as a separate tool that communicates with others through simple connections. When you build this way, it becomes easier to add new features, test changes, and fix errors. You create a flexible foundation where improvements never break existing functions. This mindset helps you build systems that are adaptable, maintainable, and always ready for innovation.
- These principles let you evolve components independently (replace a stream processor, change storage format) without a full system rewrite.
2. High-level architecture (ingest → process → serve)
- A high-level architecture is needed for real-time streaming to platform deployment because it gives you a clear view of how your entire system works together. It helps you understand how data flows from collection to delivery in real time. With this structure, you can identify where to optimize performance, reduce delays, and ensure every part connects properly. It also makes your platform easier to scale, debug, and update, keeping it stable as data moves continuously through it.
- When you design a high-level architecture, you are building a clear flow for how data moves through your system. It usually starts with ingestion, where raw data is collected from sources like users, sensors, or applications. Next comes processing, where this data is cleaned, transformed, or analyzed to make it useful. Finally, you reach the serving stage, where the processed data is delivered to users through dashboards, reports, or applications. By following this ingest, process, serve pattern, you make your system easier to understand, manage, and scale. It helps you create a smooth, reliable, and efficient path from raw data to real-time insights.
2.1 Ingest
- The ingest layer is where your system first receives data from users, sensors, or applications. A reliable and low-latency transport ensures that information flows quickly and without loss. Tools like client SDKs, WebRTC, and IoT gateways help you collect and send data smoothly from different sources. This layer must handle many types of devices and network conditions efficiently. If ingestion is slow or unstable, your real-time platform will lag, causing delayed updates and poor user experiences. Strong ingestion keeps your system fast, stable, and always ready for real-time action.
2.2 Broker / Messaging
- The broker or messaging layer is like the heart of your real-time system. It is responsible for storing and distributing events between different services safely and quickly. Tools such as Kafka, Pulsar, or other streaming services make sure no data is lost and everything is delivered in the right order. This layer provides data durability, meaning your information stays safe even if a service crashes. Without a strong messaging system, your platform could face delays, data loss, or inconsistent updates, which would affect real-time performance and reliability for users.
2.3 Processing
- The processing layer is where your data becomes useful. Stateless processing handles each event independently, like counting clicks without remembering the past, while stateful processing keeps track of previous events, such as calculating running totals or trends. Tools like Flink, Kafka Streams, and Beam help you process continuous streams of real-time data efficiently. This allows you to get instant insights and make quick decisions. Real-world examples include personalized recommendations, fraud detection, or updating live dashboards. Strong processing makes your system responsive, intelligent, and able to handle fast-moving data continuously.
2.4 Serving / APIs
- The serving layer is where your processed data reaches users quickly and efficiently. Low-latency views and caches make your applications feel fast because information is ready immediately. APIs, databases, and search indexes work together to deliver the right data to the right place. This layer can also provide machine learning features, using data to give smarter predictions or personalized experiences. A strong serving layer ensures that dashboards, apps, or notifications update instantly. By focusing on serving, you make your system responsive, reliable, and capable of giving users the best real-time experience.
- In a real-time system, you also need a control plane, observability, and security. The control plane helps you manage deployments and updates using CI/CD and GitOps, making changes smooth and reliable. Observability lets you track metrics, logs, and traces so you can spot issues and understand system behavior. Security protects your data with authentication, encryption, and policies to keep everything safe. By including these layers, you make your platform more stable, transparent, and secure, ensuring it runs smoothly for users.
3. Picking the streaming backbone: Kafka vs Pulsar (and managed services)
- Choosing the right streaming backbone is important for real-time streaming to platform deployment because it decides how your events move through the system. Tools like Kafka and Pulsar store and distribute data streams reliably, ensuring nothing gets lost and everything arrives in order. Managed services make setup and scaling easier, letting you focus on building features instead of infrastructure. The right backbone helps your system stay fast, durable, and able to handle large amounts of data. Picking carefully ensures smooth real-time processing, better scalability, and a stable platform for users.
3.1 Kafka:
a. Kafka’s Mature Ecosystem and High Throughput
- Kafka has a mature ecosystem that has been tested and improved over many years. Its high throughput allows you to handle millions of events per second without slowing down your system. This makes it ideal for real-time streaming where speed and reliability are critical. You can trust Kafka to deliver data quickly and consistently, which is why many companies rely on it for their event-driven applications, live analytics, and streaming platforms. Its strong ecosystem also gives you tools and community support to solve problems easily.
b. Connectors and Integrations
- Kafka offers a wide range of connectors and integrations that let you link it to different databases, applications, and services. This means you can move data in and out of Kafka easily without building custom solutions. As a developer, you can focus on building features instead of worrying about data transfer. These integrations make your streaming platform more flexible and efficient. They also help you combine data from multiple sources to get real-time insights, improving your analytics and decision-making.
c. Benefits of Managed Kafka Services
- Using managed Kafka services like Confluent Cloud, AWS MSK, or Redpanda Cloud removes much of the operational burden from your team. You do not have to handle setup, maintenance, or scaling manually. These services make it easier to deploy Kafka reliably and focus on your application logic. Managed offerings are also monitored continuously to ensure performance and availability. By using them, you can adopt Kafka faster and more safely, making your real-time streaming platform stable and ready for growth.
d. Self-Managed Kafka vs Managed Offering
- If you manage Kafka yourself, you have full control but must handle installation, maintenance, scaling, and monitoring. Using a managed offering takes care of all these tasks for you. This reduces mistakes and frees up time to work on your features instead of infrastructure. Managed Kafka services provide reliability, automatic updates, and support, which are crucial for real-time systems. Choosing the right approach depends on your team size and expertise, but managed services help you focus on building a fast and stable platform.
e. Examples of Large-Scale Kafka Use
- Many companies use Kafka to handle large-scale event streams like user activity, transactions, or sensor data. For example, social media apps track likes, comments, and posts in real time, while e-commerce platforms monitor orders and inventory updates instantly. Kafka allows these systems to process huge volumes of data without delays. By using Kafka, you can build platforms that are scalable, reliable, and capable of real-time analytics, helping your users get instant updates and a smooth experience.
3.2 Pulsar:
a. Geo-Replication and Multi-Tenancy
- Pulsar’s geo-replication allows you to copy data across multiple regions, so your system works reliably even if one location goes down. Multi-tenancy lets you run multiple applications or teams on the same Pulsar cluster without interference. This makes it perfect for global applications where users are spread across different regions. By using these features, you ensure that your real-time streaming platform stays available, scalable, and secure for everyone. You can handle worldwide traffic efficiently without compromising performance or data safety.
b. Separated Compute and Storage Architecture
- Pulsar separates compute and storage using BookKeeper for storage and brokers for processing events. This means you can scale storage independently from processing power, making your system more flexible and cost-effective. If you need more storage or higher throughput, you can adjust one without affecting the other. This design helps you maintain high performance and reliability as your platform grows. You can handle more users and data streams while keeping the system stable and easy to manage.
c. Pub/Sub and Queueing Semantics
- Pulsar supports both pub/sub for broadcasting messages to multiple consumers and queueing semantics for tasks that need single delivery. This makes it versatile because you can handle streaming data and task queues in one platform. You do not need separate tools for different workloads, which simplifies your system. As a developer, you can design applications that process real-time events and background tasks efficiently. Pulsar ensures your data is reliable, ordered, and delivered exactly as needed.
d. Flexibility, Scaling, and Storage Patterns
- Compared to Kafka, Pulsar offers more flexibility in how you scale and store data. You can grow storage independently from processing and replicate data globally. This allows your platform to handle different workloads without affecting performance. Its architecture supports multiple tenants and ensures smooth operation even with large traffic. By using Pulsar, you can build a system that adapts to your needs, is resilient, and maintains high performance. It gives you more control over how resources are used and scaled efficiently.
e. Efficient Scenarios for Pulsar
- Pulsar works well in situations where you need both real-time streaming and task queues. For example, a global e-commerce platform can track live orders while managing background tasks like payment processing or notifications. Its architecture makes it easier to scale storage and compute separately, saving costs and improving efficiency. Pulsar ensures that events are delivered reliably and processes run smoothly. Using Pulsar in these scenarios helps you build a fast, flexible, and robust platform capable of handling multiple workloads simultaneously.
3.3 How to choose (practical):
- a. Choose Kafka with a managed service when raw throughput and a mature ecosystem are your top priorities. You get proven tools and many connectors that simplify integration with databases and applications. Managed offerings handle maintenance, updates, and scaling so your team spends less time on ops and more time on product features. This reduces risk and speeds delivery. For large-scale event streams, this option gives you the reliability, performance, and community support you need. It fits enterprise requirements, too.
- b. Choose Pulsar when you need strong multi tenancy, easy geo replication, and built-in support for queueing alongside streaming. Its design separates storage and compute so you can scale each part independently, which saves cost and improves flexibility. You can run multiple teams or applications safely on the same platform without interference. If global replication and tenant isolation matter for your product, Pulsar gives you these features out of the box and simplifies operating complex multi-region streaming systems reliably.
- c. Prefer managed offerings whenever possible because they reduce the time you spend on operations and let you iterate faster. Providers handle setup, scaling, backups, and upgrades, which lowers risk and makes deployments more predictable. This means you can test ideas, get feedback, and improve features without being blocked by infrastructure work. For small teams or early stages, managed services let you move quickly while still delivering reliable performance. Later, if you have specific needs, you can evaluate self-managed options.
4. Client to server: WebRTC, WebTransport, and low-latency ingestion
- Technologies like WebRTC and WebTransport are essential for real-time streaming to platform deployment because they allow data to move instantly between the client and the server. These tools reduce latency, meaning users see updates or changes almost immediately. Low-latency ingestion ensures that every event, message, or video frame is captured and processed without delay. This makes your platform faster, responsive, and ideal for live experiences such as online gaming, video calls, or real-time dashboards where every second matters.
- For browser and mobile real-time streams such as audio, video, or sensor data, the web is improving beyond traditional WebRTC. New technologies like WebTransport offer lower latency, better control, and support for multiple data streams at once. This makes it easier to build smooth, interactive apps that respond instantly. WebTransport is being developed by the IETF as a modern standard for two-way, low-delay communication between the client and server. You can use WebRTC for media-heavy uses and WebTransport or WebSockets for fast real-time data channels.
a. WebRTC + selective forwarding (SFU) or managed real-time platform
- For live video conferencing, you should use WebRTC with a selective forwarding unit, also called SFU, or a managed real-time platform. This setup helps you send and receive multiple video and audio streams without a heavy network load. The SFU handles stream distribution efficiently so that you get smooth and reliable communication. A managed platform also reduces your setup and maintenance time while ensuring low delay, better media quality, and easy scaling for many users.
b. WebTransport or UDP-based transports with a fallback to WebSocket/HTTPS
- For high-frequency telemetry such as game inputs or IoT sensor bursts, you should use WebTransport or UDP-based transports. These protocols allow faster data transfer with less delay, which is very important when every millisecond counts. If these options are not available, you can safely fall back to WebSocket or HTTPS for stable communication. This flexibility ensures your app continues to perform efficiently even with changing network conditions or client setups.
- You should always implement congestion control and server ingestion backpressure in your system. Congestion control helps you manage how much data is sent when the network is crowded so that your stream does not freeze or lag. Backpressure ensures that the server can handle the incoming data rate properly. Both help prevent overload, maintain stable real-time streaming, and protect system performance during heavy traffic or rapid data flow.
5. Stream processing styles: stateless, stateful, and exactly-once
- When you work with stream processing, you deal with continuous flows of data events that must be handled correctly and efficiently. You will often use stateless, stateful, or exactly once processing depending on your system’s needs. Stateless processing treats each event independently, stateful processing remembers past events, and exactly once ensures every event is processed only once in time. By mastering these styles, you build systems that are more accurate, reliable, and ready for real-time analytics.
5.1 Stateless transforms
- Stateless processing means you handle each event separately without storing any previous data. Each message is processed independently, which makes your system faster and easier to scale. You use operations like mapping, enrichment, and filtering to modify or clean data as it moves through the platform. Running these tasks with serverless functions or lightweight stream workers helps manage scaling and performance automatically. This approach works well when you do not need historical context. It is ideal for real-time notifications, log filtering, or data transformation in live applications where speed and simplicity matter most.
5.2 Stateful processing
- Stateful processing means you keep track of information from previous events so you can make smarter decisions. You use this when you need to connect or compare data over time. You often work with windowing, joins, and aggregations to group or combine data streams. Tools like Apache Flink, Kafka Streams, and Beam help you manage this stored information safely and reliably. You use stateful processing when accuracy and context matter, such as tracking user sessions, calculating averages, or detecting trends in live data streams.
5.3 Exactly-once semantics
- Exactly once semantics means each event in your data stream is processed only once, even if there are failures or retries. This is very important in financial systems or metrics tracking, where duplicate transactions or counts can cause serious errors. Modern tools like Kafka and Flink help you achieve this by using idempotence and transactional guarantees, which prevent duplicate processing. You must also design your sinks and downstream systems to handle data carefully so that no event is repeated. This ensures your results stay accurate, reliable, and consistent across the entire streaming process.
- When choosing a stream processing framework, you should consider latency, state size, and operational complexity. If your system needs complex stateful processing with large amounts of data, Flink is a strong choice because it handles state efficiently and reliably. If you are already using Kafka, Kafka Streams fits well since it integrates tightly and is easier to set up. For less operational effort, you can use cloud-native managed services for Flink or Kafka, which handle scaling, maintenance, and monitoring. Picking the right framework ensures your real-time platform is fast, reliable, and easy to manage.
6. Data topology: event sourcing, CQRS, and materialized views
- For real-time streaming to platform deployment, you need a clear data topology to organize how information flows and is used. Event sourcing records every change as an immutable event, making it easy to replay or audit data. CQRS separates commands that change data from queries that read data, improving performance and scalability. Materialized views store precomputed results for fast access, so your users get instant updates. Together, these patterns make your system reliable, responsive, and easy to maintain, while allowing real-time insights, scalable operations, and consistent data for all users. Architectural patterns that simplify real-time apps:
6.1 Event Sourcing
- Event sourcing means you store every change in your system as an event, making these events the source of truth for your data. This allows you to replay past events to reconstruct system state or fix mistakes, which is helpful for temporal debugging. Tracking all events gives you a complete history, making analytics, monitoring, and system recovery easier. Many applications, like financial platforms or order management systems, use event sourcing to improve reliability and auditability. By keeping a detailed record of every action, your system becomes more transparent, robust, and ready for future analysis or corrections.
6.2 CQRS (Command Query Responsibility Segregation)
- CQRS, or Command Query Responsibility Segregation, means you separate commands that change data from queries that read data. By doing this, your write model focuses on handling updates efficiently, while your read model is optimized for fast queries. This improves performance because reading and writing do not compete for resources, and it increases scalability since each model can grow independently. When combined with event sourcing, CQRS ensures that all changes are recorded as events, keeping the system consistent. You see this in financial systems, real-time dashboards, or any app that needs accurate and fast data access.
6.3 Materialized views/feature stores
- Materialized views or feature stores store precomputed data in a way that is optimized for reading, so your system can respond to queries very quickly. Tools like Redis, Druid, or materialized Kafka topics help you save this data efficiently. By having the results ready in advance, your users get low-latency reads and fast updates without waiting for heavy computations. This is useful for real-time analytics, live dashboards, or powering machine learning features that need immediate data. Using materialized views makes your platform more responsive, efficient, and able to handle high traffic without slowing down.
- When you design change capture and retention, start by asking how long events must be stored. Consider if you need reprocessing to rebuild the state or fix errors. Define the SLA for replay so you know how quickly past events must be available. Retention policies help manage storage and system performance. Reprocessing ensures accuracy and lets you recover from mistakes. Replay SLAs give your team and users confidence that historical data is accessible when needed. Clear answers make your platform more reliable, transparent, and easier to maintain.
7. Deployment platform in 2025: Kubernetes + GitOps as the de facto stack
- In 2025, Kubernetes will still be the main choice for running containerized streaming systems. Many organizations use managed Kubernetes services like GKE, EKS, or AKS to simplify operations. They also rely heavily on observability tools to monitor performance and security tools to protect workloads. Kubernetes helps you orchestrate containers efficiently and scale your applications reliably. It also integrates with logging, metrics, and tracing to give full visibility. Using Kubernetes makes your streaming platform more stable, scalable, and easier to manage in production.
- For deployment delivery, GitOps uses a pull-based approach where clusters automatically reconcile with the Git repository. Tools like Argo CD help you sync declarative manifests into clusters without manual steps. Argo CD provides versioned platform state, auditable deploys, and safer rollbacks. It ensures your deployments are reliable and consistent. GitOps reduces human errors and improves team confidence. Teams can track changes easily, restore previous states, and maintain transparency. This approach has become popular because it makes platform management simpler, safer, and more automated.
7.1 Recommended platform pattern:
a. Kubernetes for Microservices and Stream Processors
- Kubernetes helps you deploy microservices, stream processors, and serving layers efficiently in a unified platform. It manages scaling, failover, and resource allocation, so your system stays resilient even under heavy load. Running stream processors as K8s operators simplifies deployment because operators automate tasks like configuration, scaling, and updates. Operators monitor the system and ensure your streams keep running smoothly. Kubernetes also supports real-time platforms by automating deployments, handling crashes, and making scaling predictable. Microservices and stream processors can communicate seamlessly, enabling fast data flow and processing. Using Kubernetes makes your platform more manageable, flexible, and ready for growth.
b. Specialized Operators and Managed Brokers
- Specialized operators for Kafka or Pulsar help you manage complex brokers by automating tasks like deployment, scaling, and monitoring. Operators ensure your streams stay reliable and reduce manual errors. Managed brokers provide similar benefits without requiring you to operate the infrastructure yourself. Managed services handle updates, backups, and scaling automatically. They are also especially useful for small teams or when your team lacks deep operational expertise. You can focus on building features instead of maintaining clusters. Operators give more control, while managed services save time and reduce risks. Choosing the right approach depends on your team size, expertise, and system complexity.
c. GitOps with Argo CD and Flux
- GitOps uses tools like Argo CD or Flux to automatically manage your application and platform manifests. These tools continuously compare the state in Git with the live system and apply changes when needed. GitOps ensures your deployments are consistent, auditable, and versioned. Storing everything in Git improves version control, rollback, and traceability, so you can see who made changes and restore previous states easily. GitOps makes deployments more predictable, reliable, and automated, reducing human errors. Teams can update microservices, stream processors, and serving layers safely. This approach helps you maintain a stable and transparent platform for real-time streaming systems.
8. Observability: OpenTelemetry, metrics, traces, and logging
- For real-time streaming to platform deployment, observability helps you understand how your system behaves and performs. Tools like OpenTelemetry collect metrics, traces, and logs from every part of your platform. Metrics show system health and resource usage, traces reveal how requests flow through services, and logs capture detailed events for debugging. Observability helps you detect issues quickly, optimize performance, and maintain reliability. By using these tools, you can monitor microservices, stream processors, and serving layers effectively. Strong observability ensures your platform stays responsive, stable, and capable of handling real-time data efficiently for users.
8.1 Key observability recommendations:
a. Capturing Latency and Message Paths
- Measuring producer and consumer latency is crucial because it shows how fast events move through your system. Tracking the end-to-end message path helps you identify bottlenecks and areas where delays happen. You should monitor critical topics and high-priority messages to ensure they are delivered reliably and on time. Latency data can help you optimize performance by adjusting resources or improving configurations. This improves the overall user experience because updates appear faster and systems respond more smoothly. By capturing these metrics, you gain better visibility, can troubleshoot issues quickly, and maintain a responsive and stable real-time streaming platform for all users.
b. Correlating Logs, Metrics, and Traces
- Using consistent trace IDs helps you link logs, metrics, and traces across your real-time platform. Including event IDs in logs makes debugging easier because you can follow a single event through every service it touches. Correlating these different telemetry types gives you a complete view of system behavior and helps spot hidden issues quickly. When logs, metrics, and traces are connected, you can detect bottlenecks, failed events, or delays faster than looking at one type alone. This approach improves troubleshooting, ensures reliability, and helps you maintain a stable and responsive platform that handles real-time data efficiently for users.
c. Sampling and Adaptive Telemetry
- In high-volume data streams, sampling means collecting only a portion of events instead of everything. Adaptive telemetry adjusts the amount of data you collect based on system load or importance. These techniques help control costs while still capturing the most important insights. You might use full telemetry for critical topics and sampling for less important streams. Adaptive telemetry ensures your monitoring remains efficient even when traffic spikes. For example, in online gaming or IoT sensor networks, sampling prevents your system from being overwhelmed. Combining these approaches helps you keep visibility, maintain performance, and monitor real-time data without overspending on storage or processing resources.
9. CI/CD, GitOps, and platform code
- For real-time streaming to platform deployment, CI/CD automates building, testing, and deploying your code, making releases faster and more reliable. GitOps ensures that your platform state and application manifests are stored in Git, allowing automatic reconciliation and easy rollbacks. Using platform code lets you treat infrastructure and configuration like software, giving version control and repeatable deployments. Together, these practices reduce human errors, improve consistency, and speed up delivery. Teams can update microservices, stream processors, and serving layers safely. This approach makes your system more scalable, transparent, and capable of handling complex real-time workloads efficiently for users.
9.1 Continuous Integration (CI) for Real-Time Streaming
a. Build Artifacts
- Building artifacts in CI is important because it packages your code into a consistent, deployable form. Each artifact contains everything your service needs, including dependencies and configuration. By automating artifact creation, you reduce manual mistakes and ensure that every environment runs the same code. Artifacts also make scaling easier because you can deploy identical packages across multiple servers. This helps your real-time streaming platform stay stable and predictable. Reliable artifacts give you confidence in every deployment and simplify maintenance, making your system more efficient, robust, and ready for updates.
b. Contract Tests for Publishers and Consumers
- Running contract tests ensures that publishers and consumers can communicate correctly. These tests verify that the data format and expectations match between services. Contract testing prevents breaking changes from being deployed into production, which could disrupt your streaming pipelines. By catching issues early in CI, you save time and avoid downtime. Contract tests maintain data consistency, improve system reliability, and help your team deliver safe updates. This practice keeps your real-time streaming platform running smoothly while enabling continuous development and faster releases.
c. Schema Compatibility
- Testing schema compatibility ensures that changes in event structures do not break existing consumers. Schema validation checks whether updates are backward compatible and safe to deploy. By running these tests in CI, you prevent runtime errors and maintain platform stability. Schema testing allows your team to make changes confidently while keeping data flowing smoothly. It also supports data quality, reduces risk, and ensures that your real-time streaming platform remains reliable for all users. This practice is essential for evolving systems that handle complex event-driven data streams.
d. CI Pipelines Detecting Issues
- CI pipelines automatically detect problems before deployment, making your system more reliable. They build artifacts, run contract tests, and check schema compatibility for every code change. This ensures that only tested and safe code reaches production. Pipelines can also run additional checks, like unit tests and integration tests, to catch errors early. By using automated pipelines, you save time and reduce human error. This helps maintain a stable, predictable, and efficient real-time streaming platform while supporting rapid feature development and continuous delivery.
9.2 Continuous Deployment (CD) and GitOps for Real-Time Streaming
a. Applying Manifests with Argo CD
- Using Argo CD automatically applies manifests from Git to your clusters, ensuring the live system matches the desired state. This reduces manual errors and keeps deployments consistent across environments. Argo CD continuously monitors the system and fixes any drift from Git automatically. Automating manifest application saves time and allows your team to focus on developing features instead of managing deployments. This approach provides auditability, predictability, and helps maintain a reliable real-time streaming platform while ensuring all services are synchronized and up to date.
b. Health Checks
- Health checks monitor whether your applications and services are running correctly after deployment. They detect failures quickly and trigger alerts or automatic rollbacks to prevent downtime. Health checks protect critical microservices and stream processors from affecting users. By monitoring system health continuously, you can respond to issues faster and prevent cascading failures. Health checks improve reliability, ensure stability, and give your team confidence that your real-time streaming platform remains responsive and available for all users.
c. Progressive Deployment Strategies
- Progressive deployment strategies, like canary and blue/green, reduce risks when releasing new versions of software. Canary releases allow you to test updates on a small subset of users before full rollout. Blue/green deployments let you switch between old and new versions safely with minimal downtime. These strategies minimize the impact of errors on end users. Using progressive deployment ensures stability, reliability, and safer updates while enabling rapid feature delivery. Teams can deploy confidently knowing problems can be caught early without affecting the full platform.
d. Argo Rollouts for Safe Deployments
- Argo Rollouts helps you deploy microservices or stream processors with minimal risk by automating canary and blue/green strategies. It monitors performance and error rates during deployment, adjusting traffic to new versions safely. Rollouts reduce manual intervention and ensure updates happen smoothly across all clusters. Using Argo Rollouts improves deployment safety, maintains system reliability, and allows your real-time streaming platform to evolve without causing downtime. This approach gives your team confidence to release features quickly while keeping users unaffected.
9.3 Policy as Code for Platform Safety
- Using policy as code with tools like Kyverno or OPA helps enforce rules automatically when resources are created or updated. Policies can deny plaintext secrets, enforce network policies, and restrict host access to keep your platform secure. This prevents mistakes or unsafe configurations from entering the system. By applying rules at admission time, you catch issues before they affect running services. Policy as code improves security, ensures compliance, and maintains a reliable real-time streaming platform while giving your team confidence in safe deployments.
10. Security, governance, and compliance
- For real-time streaming to platform deployment, security protects your data and systems from unauthorized access and attacks. Governance ensures that teams follow policies and best practices when building and operating the platform. Compliance makes sure your platform meets legal and industry requirements. Together, they reduce risks and maintain trust with users and stakeholders. By implementing strong security controls, clear governance rules, and compliance checks, you keep your microservices, stream processors, and serving layers safe, reliable, and auditable while supporting long-term growth and operational excellence.
10.1 Authentication & Authorization:
- You protect your real-time platform by using TLS to encrypt all data in motion so that no one can intercept it. For service-to-service communication, mTLS adds another layer of trust by verifying both sides of the connection. Through RBAC, you assign clear roles and permissions so that only authorized users or services can access brokers or Kubernetes resources. When you combine these methods, you reduce the risk of unauthorized access. This approach keeps your streaming systems, microservices, and data pipelines safe from internal and external threats.
10.2 Encryption:
- You must use encryption at rest to make sure your stored data stays safe even if someone gets access to your disks. By encrypting data, you turn readable information into an unreadable form, which keeps it secure. Topics that include PII must always be encrypted so personal details cannot be exposed. Tiered storage also helps you manage both performance and security together. It allows you to store recent data in faster systems while keeping older data safely encrypted in cheaper, long-term storage systems.
10.3 Schema Governance:
- You rely on Schema Governance to keep your data consistent and reliable across all services. A Schema Registry helps you manage how data is structured and ensures every producer and consumer follows the same rules. Using formats like Avro, Protobuf, or JSON Schema prevents mismatched data and application failures. When you maintain compatibility between versions, you avoid breaking older consumers. This approach saves time during updates and reduces bugs by catching errors early before they reach your real-time data pipelines or streaming systems.
10.4 Policy & auditing:
- You maintain policy and auditing to ensure your platform stays secure, transparent, and accountable. Through Git logs, you can trace every change made to the system and identify who performed it. GitOps adds automation by storing all platform configurations in Git, which gives you an immutable audit trail that cannot be easily altered. Collecting detailed audit logs supports compliance and helps you meet security standards. When something goes wrong, these records allow you to review, trace, and fix issues with confidence and accuracy.
11. Cost, resiliency, and SRE practices
- You need cost management, resiliency, and SRE practices to keep your real-time platform efficient and stable. Cost awareness helps you optimize resource usage and avoid unnecessary spending. Resiliency ensures that your system keeps running even when failures occur. With SRE principles, you focus on automation, monitoring, and error budgets to maintain reliability. Together, these practices help you balance performance, cost, and uptime so your streaming platform remains fast, dependable, and sustainable under growing workloads.
11.1 Right-size retention:
- You manage right-size retention to balance both cost and performance in your real-time streaming system. By using tiered storage, you can separate data based on how frequently it is accessed. Recent or frequently used information stays in hot storage, which offers faster access. Older data moves to cold storage, which costs less but still keeps the data available when needed. Platforms like Kafka and managed services make this process easier by automatically shifting older segments to cheaper object storage, helping you save money without losing data availability.
11.2 Autoscale Consumers
- You use autoscale consumers to keep your system efficient when workloads rise or fall. Adaptive scaling allows your consumers to adjust automatically based on traffic levels. When more data flows in, new consumers join to handle the load. As traffic decreases, some consumers stop, saving resources. It is also important to manage partition assignments carefully so all consumers share work evenly. This prevents sudden overloads known as the thundering herd effect and ensures your real-time platform stays stable, responsive, and cost-effective during both peak and low demand.
11.3 Chaos and Disaster Recovery
- You apply chaos and disaster recovery practices to make your streaming platform stronger and more reliable. Through chaos testing, you intentionally cause small failures to observe how your system reacts. This helps you discover weak points before real issues happen. Regularly testing failovers, partition rebalances, and regional recovery keeps your platform ready for unexpected events. Geo-replication ensures that data remains available even if one region goes down. By practicing recovery often, you build confidence that your real-time system can survive disruptions and continue running smoothly.
12. Edge, ML inference, and near-user compute
- In 2025, you need edge computing and ML inference to make real-time streaming faster and more efficient. Processing data near the user reduces delay and improves interaction speed. Local model inference allows quick decisions without always depending on central servers. Prefiltering at the edge also cuts unnecessary data transfer, saving bandwidth and cost. Centralized streaming platforms still play a key role in global aggregation and model retraining, ensuring that insights remain accurate and systems stay up to date across all regions.
13. Testing strategies for streaming systems
- You need strong testing strategies to make sure your real-time streaming system works correctly under different conditions. Unlike simple applications, streaming platforms require continuous data handling and complex event processing. Unit tests alone cannot capture timing, ordering, or data consistency issues. By including integration tests, load tests, and end-to-end validations, you can detect hidden problems early. Careful testing ensures your platform stays reliable, scalable, and efficient as it processes massive amounts of live data every second.
13.1 Contract Tests
- You use contract tests to make sure producers and consumers share the same understanding of data structures and message formats. These tests confirm that schemas and topic semantics remain compatible when new versions are introduced. A mismatch can cause message failures or corrupted data in your system. By testing contracts early, you prevent problems that could break communication between services. This approach gives you confidence that all components work together smoothly, ensuring your real-time streaming platform stays reliable and consistent during deployments or updates.
13.2 Replay Tests
- You perform replay tests to check how your system handles old data streams safely. By replaying historical topics in a test environment, you can confirm that your processing logic is idempotent, meaning it produces the same result even when data is reprocessed. This helps detect hidden issues like duplicate records or incorrect state updates. Through replaying, you also validate how your system manages the timing and ordering of events. These tests give you assurance that your platform can recover from errors or reprocess data without breaking accuracy.
13.3 Integration and Load Tests
- You rely on integration tests to confirm that all system components communicate and function correctly together. These tests reveal whether your producers, brokers, and consumers stay synchronized under normal conditions. Load tests push your system with heavy data flow to simulate real-world workloads. Watching consumer lag during these tests helps you identify bottlenecks and fine-tune performance. When you combine both methods, you build a platform that runs smoothly even under stress, ensuring your real-time streaming pipelines stay responsive and efficient as data volume grows.
13.4 Chaos and Chaos-Ops
- You use chaos and chaos-ops testing to make your streaming platform resilient against unexpected failures. During these tests, you intentionally cause issues like broker outages, partition loss, or sudden consumer lag spikes. Observing how the system reacts helps you understand its weak points. It also teaches you how to recover quickly from disruptions. Practicing chaos regularly builds confidence that your platform can handle real-world problems without collapsing. This mindset strengthens your real-time infrastructure, keeping it stable and reliable even under unpredictable conditions.
13.5 Tooling
- You use local ephemeral clusters of tools like Kafka or Pulsar in your CI (Continuous Integration) setup to test streaming systems efficiently. These clusters are temporary and easy to create or destroy, helping you avoid complex setups. By keeping them lightweight and deterministic, you make sure tests always run the same way and produce consistent results. This approach helps you quickly detect issues before deployment. It also improves developer productivity and ensures your real-time streaming platform remains stable across updates.
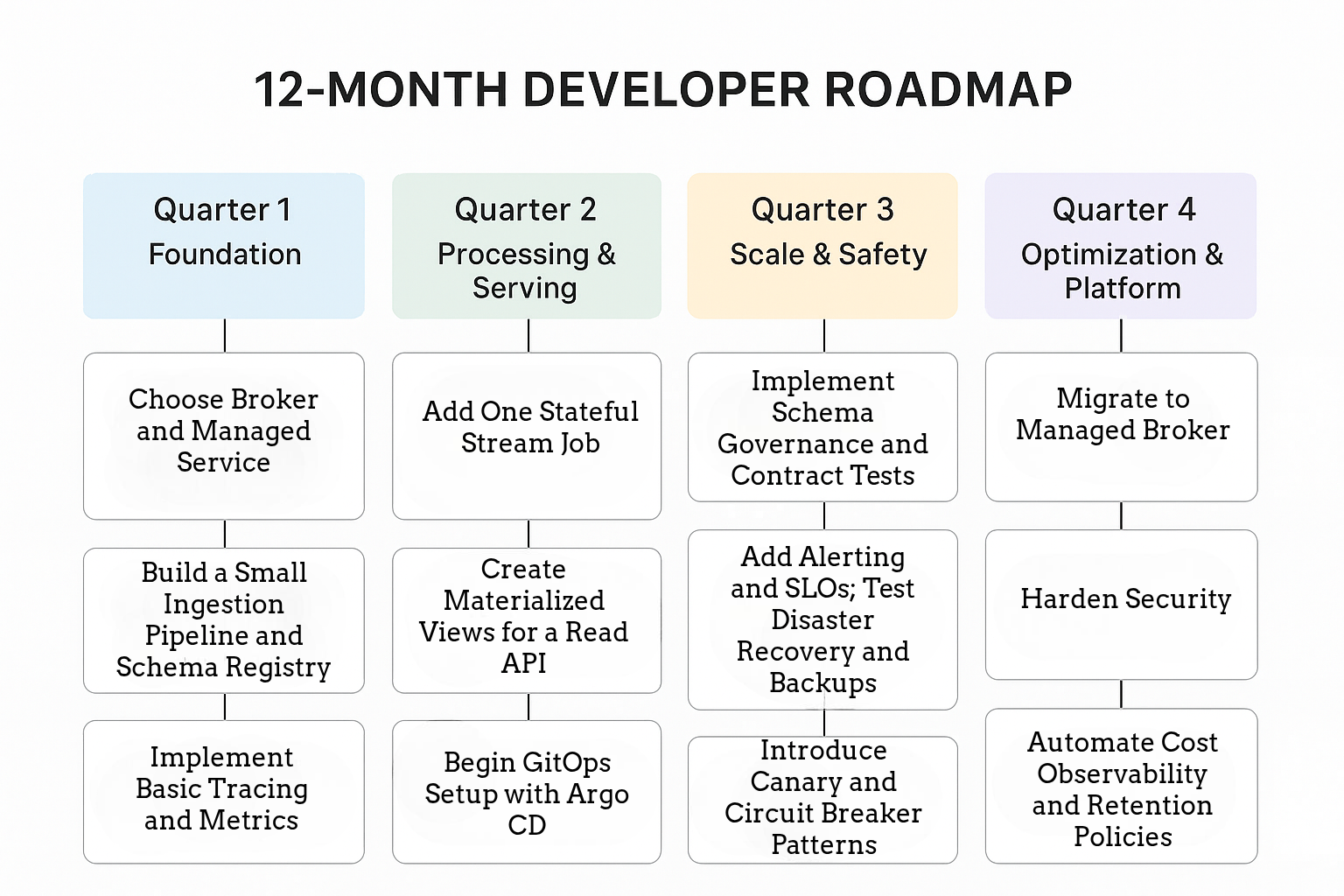
14. A practical 12-month developer roadmap (quarterly milestones)
- You need a 12-month developer roadmap to move smoothly from real-time streaming to full platform deployment. It helps you plan progress step by step and stay focused on clear quarterly goals. Each milestone allows you to measure growth and fix gaps early. By following a structured timeline, you avoid confusion and maintain steady improvement. This roadmap also keeps your team aligned, ensures consistent innovation, and helps you build a scalable and reliable streaming platform ready for future challenges.
14.1 Quarter 1: Foundation
a. Choose Broker and Managed Service
- When you begin, you must choose between Kafka and Pulsar for your streaming platform. Both offer strong scalability and low latency, but their architectures differ. Kafka is often preferred for its mature ecosystem, while Pulsar is praised for multi-tenancy and message durability. You should also decide if using a managed service is better than self-hosting. Managed services reduce maintenance and improve reliability. However, self-hosted systems give more control and flexibility over performance and cost.
b. Build a Small Ingestion Pipeline and Schema Registry
- You start by creating a small ingestion pipeline to collect and process incoming real-time data. This setup helps you understand data flow before scaling further. The schema registry plays a major role by storing and managing data formats used in messages. It ensures that producers and consumers communicate with consistent structures. By enforcing schema validation, you prevent data mismatches that could break your applications. Over time, this makes your system more stable and reliable.
c. Implement Basic Tracing and Metrics
- Adding tracing and metrics gives you clear visibility into your streaming system. You can track how data moves through each component and identify delays early. With OpenTelemetry, you can collect traces and metrics across services to monitor their performance. This helps you detect bottlenecks, measure latency, and ensure smooth message flow. By understanding these insights, you improve troubleshooting speed and maintain system health. Regular monitoring also builds trust in your platform’s efficiency and resilience.
14.2 Quarter 2: Processing & Serving
a. Add One Stateful Stream Job
- You add a stateful stream job to handle data that depends on past events, which is crucial for real-time analytics. Tools like Flink or Kafka Streams keep durable state, meaning your data and calculations survive failures. Stateful jobs help with aggregations, windowing, or session tracking, allowing you to compute insights across multiple events. By maintaining the state reliably, you can ensure accuracy in outputs even if the system restarts. This approach improves the stability and trustworthiness of your streaming platform.
b. Create Materialized Views for a Read API
- You build materialized views to make read queries faster and reduce pressure on your main streaming system. Using Redis or a search index precomputes results so your API can respond instantly. Materialized views help deliver low-latency data for dashboards, search, or user-facing applications. They also reduce load on processing pipelines because queries do not recompute data every time. By designing views carefully, you maintain system performance, scalability, and a smooth user experience for real-time data applications.
c. Begin GitOps Setup with Argo CD
- You start GitOps using Argo CD to automate the deployment of manifests for your streaming platform. Storing manifests in Git provides version history, auditability, and safer rollbacks when changes are needed. Argo CD continuously monitors the system and reconciles differences automatically, reducing manual errors. By implementing GitOps, you ensure consistent deployments, faster iterations, and reliable updates across clusters. This practice improves operational efficiency, traceability, and confidence in your real-time streaming platform as it grows and evolves.
14.3 Quarter 3: Scale & Safety
a. Implement Schema Governance and Contract Tests
- You implement schema governance to make sure producers and consumers always agree on data formats in your streaming system. By enforcing schemas, you prevent mismatched messages that could break pipelines or applications. Contract tests help verify that changes do not disrupt downstream consumers. This ensures your system remains reliable even as data evolves. When a new feature or schema version is added, testing compatibility first avoids production errors. These practices make your platform more stable, predictable, and easier to maintain.
b. Add Alerting and SLOs; Test Disaster Recovery and Backups
- You add alerting to notify you when issues arise and track system health. Setting clear SLOs defines expected reliability and performance levels. Testing disaster recovery ensures that backups restore data quickly after failures. This helps you prepare for unexpected outages or data loss. By regularly validating recovery procedures, you maintain uptime and prevent disruptions. Alerting combined with tested recovery practices makes your streaming platform more resilient, trustworthy, and capable of handling real-time workloads safely.
c. Introduce Canary and Circuit Breaker Patterns
- You can use Canary deployments to release new updates gradually, reducing risk for your streaming platform. This allows you to monitor performance and detect issues before they affect all users. Circuit breakers protect your system by stopping failures in one service from cascading to others. Together, these patterns improve reliability and maintain smooth operations under high load. They also give your team confidence to deploy new features safely. By combining gradual rollout with failure isolation, you keep your platform stable, resilient, and responsive.
14.4 Quarter 4: Optimization & Platform
a. Migrate to Managed Broker
- You migrate to a managed broker like Kafka or Pulsar to reduce operational complexity and save time on maintenance. Managed services handle scaling, backups, and monitoring automatically, letting you focus on building features instead of managing infrastructure. By moving to a managed setup, you avoid common pitfalls like cluster failures or configuration errors. This approach improves reliability, availability, and developer productivity. Even complex tasks like upgrading versions or managing partitions become easier, ensuring your real-time streaming platform remains stable and scalable as your workloads grow.
b. Harden Security
- You strengthen security to protect your real-time streaming system from internal and external threats. Using mTLS ensures secure service-to-service communication and prevents unauthorized access. Managing secrets safely avoids accidental exposure of sensitive credentials. Enforcing rules through policy as code ensures consistent security standards across your platform. Together, these practices protect data, maintain trust, and support compliance. By combining authentication, authorization, and automated policy checks, you make your platform more resilient, reliable, and safe for handling high-volume or sensitive streaming data.
c. Automate Cost Observability and Retention Policies
- You automate cost observability to track resource usage and control spending efficiently. Monitoring costs continuously helps you identify areas where resources are underutilized or overprovisioned. Defining retention policies ensures old data moves to cheaper storage while keeping important data accessible for analytics. Tiered storage and automated cleanup reduce waste and maintain performance. By combining cost visibility with smart retention, you make your platform sustainable and efficient. This approach allows you to scale safely while controlling expenses and ensuring long-term operational reliability. This roadmap lets developers iterate safely, prove value, and progressively reduce operational debt.
15. Toolset cheat-sheet (developer edition)
- You need a toolset cheat-sheet to quickly reference the essential technologies for building and deploying a real-time streaming platform. It helps you remember which tools handle ingestion, processing, serving, monitoring, and security. By having everything in one place, you save time and reduce mistakes while developing. Cheat-sheets also guide you in selecting the right tool for each task and ensure consistent practices across your team. This makes your platform more efficient, reliable, and easier to maintain as it grows.
15.1 Broker:
- You choose a broker because it is the core of your streaming platform. Kafka offers a mature ecosystem, high throughput, and many integrations. Pulsar provides built-in geo-replication and multi-tenancy with separate storage and compute. Managed services like Confluent Cloud, MSK, or Redpanda reduce operational work and improve reliability. By picking the right broker, you ensure your platform can handle large-scale data efficiently. Reliability, scalability, and ecosystem support are all crucial for maintaining smooth real-time processing.
15.2 Processing:
- You use processing frameworks to handle real-time streams efficiently. Stateful processing maintains context across events, while stateless processing handles each event independently. Tools like Flink, Kafka Streams, ksqlDB, or Beam let you perform aggregations, joins, and transformations. Proper selection depends on latency requirements, state size, and operational complexity. By implementing the right framework, you can compute insights quickly and reliably. Stream transformations help deliver accurate, timely data for analytics and downstream applications.
15.3 Client transport:
- You choose client transport to control latency and interactivity between users and servers. WebRTC is best for media-heavy applications like video calls. WebTransport or WebSocket provides low-latency channels for sending data like telemetry or game inputs. By selecting the right transport, you ensure smooth user experiences and accurate event delivery. Proper client communication reduces lag and maintains real-time responsiveness. This decision is critical for interactive apps that need high performance and minimal delay.
15.4 Kubernetes + Platform:
- You use Kubernetes to manage microservices, stream processors, and other platform components. Managed services like EKS, GKE, or AKS reduce operational burden by handling upgrades, scaling, and reliability automatically. Clusters can run multiple workloads efficiently while providing isolation and observability. By using managed K8s, you ensure the smooth deployment of streaming jobs and microservices. This approach also improves developer productivity and reduces the risk of configuration mistakes. Kubernetes makes scaling your real-time platform easier and more predictable.
15.3 Deployment:
- You implement GitOps with tools like Argo CD or Flux to automate the deployment of your platform. Storing manifests in Git gives you version control, auditability, and safer rollbacks. These tools automatically sync cluster state with Git, reducing human errors. By using GitOps, you maintain consistent, repeatable deployments across environments. It also improves collaboration within your team and ensures that updates are deployed safely. Automated deployments make your streaming platform more reliable and easier to manage.
15.4 Observability:
- You add observability to monitor performance, latency, and failures in your streaming system. OpenTelemetry collects traces and metrics, Prometheus stores metrics efficiently, and Grafana visualizes data for easy analysis. By tracking system behavior, you can detect bottlenecks and troubleshoot issues quickly. Observability also helps maintain service-level objectives and improve uptime. Combining metrics, logs, and traces ensures full visibility into your platform. This practice supports smooth real-time processing and helps maintain a stable, reliable streaming environment.
15.5 Schema & Governance:
- You implement schema governance to maintain compatibility between producers and consumers. Schema Registry ensures that message formats are validated and backward compatible. OPA or Kyverno enforces policy-as-code, securing your platform by applying rules automatically. Proper governance prevents data mismatches and ensures safe deployments. It also improves auditability and compliance with organizational standards. By combining schema enforcement with automated policies, you make your streaming platform safer and more predictable. This protects both data quality and operational stability.
15.6 Testing:
- You run contract tests to verify that producers and consumers remain compatible. Replay harnesses let you test historical events to ensure idempotency and correctness. Chaos testing simulates failures like broker crashes or partition loss to validate system resilience. Testing reduces the risk of downtime and ensures smooth real-time processing. By applying these methods, you detect issues early and improve confidence in platform reliability. Comprehensive testing makes your streaming platform robust under both normal and extreme conditions.
15.7 Security:
- You secure your streaming platform using mTLS to encrypt communication between services. KMS manages sensitive secrets safely, and network policies isolate workloads to prevent unauthorized access. RBAC controls which users or services can perform actions on the platform. By combining encryption, access control, and policy enforcement, you protect data integrity and maintain compliance. Security measures prevent breaches and minimize risks while enabling smooth operations. Strong security ensures your real-time streaming system remains trustworthy and resilient.
16. Realistic tradeoffs you’ll face
- You must understand tradeoffs when building a real-time streaming platform because no solution is perfect for every scenario. Choosing latency over durability may speed up processing but increase the risk of data loss. Opting for managed services reduces operational work but limits fine-grained control. Balancing cost, scalability, and reliability requires careful decision-making. By evaluating tradeoffs, you make informed choices that match your platform goals. Awareness of these compromises helps you design a system that is efficient, resilient, and practical for real-world workloads.
16.1 Simplicity vs Capability
- You face a tradeoff between simplicity and capability when choosing a broker. Kafka is easier to understand and has a mature ecosystem with many integrations. It is ideal if you want predictable behavior and quick adoption. Pulsar offers advanced features like geo-replication, multi-tenancy, and separated storage, which provide flexibility for complex use cases. Managing Pulsar can be a more challenging operationally. By evaluating your team’s expertise and project requirements, you can choose a solution that balances ease of use with powerful features while keeping your platform stable and scalable.
16.2 Managed vs Self-Managed
- You must decide between managed services and self-managed clusters for both streaming and Kubernetes. Managed platforms reduce operational workload and speed up deployment of new features. They also help maintain reliability and reduce the number of platform engineers needed. Self-managed clusters give you complete control and can be cheaper in some cases, but they require ongoing maintenance. By weighing cost, effort, and team capacity, you can choose the right approach that ensures your real-time streaming platform remains efficient, scalable, and easy to operate.
16.3 Latency vs Cost
- You face tradeoffs between latency and cost when designing your streaming system. Reducing retention or using more caching lowers delay but increases CPU and I/O usage. Heavier batching reduces resource consumption, saving money, but adds delay in event delivery. Some applications, like financial transactions or telemetry, need low latency, while others can tolerate small delays for lower costs. By balancing performance and expense, you ensure your platform delivers real-time results while staying sustainable. Careful choices make your streaming system both efficient and cost-effective.
17. Checklist for launching your first production real-time pipeline
- You need a checklist to ensure your first real-time pipeline is reliable and ready for production. Defining events and schemas, selecting a broker, and setting up topics ensure your data flows smoothly. Instrumenting producers, configuring stateful processors, and enabling GitOps prepare your system for scale and automation. Adding observability, alerting, and security helps monitor performance and protect data. Finally, testing disaster recovery, load, and chaos scenarios ensures resilience. By following a checklist, you reduce mistakes, improve reliability, and make your streaming platform production-ready.
a. Defined Events and Schema
- You define events clearly so everyone knows what data is being produced. Storing schemas in a registry ensures producers and consumers remain compatible. Compatibility checks prevent broken pipelines when data formats change. By having clear definitions, you avoid errors and make debugging easier. Event consistency is vital for analytics, dashboards, and downstream systems. Proper schema governance ensures your real-time streaming platform can scale safely without breaking consumers. It also improves communication between developers and reduces operational risks.
b. Broker Chosen and Initial Topics
- You choose a broker like Kafka or Pulsar to manage message flow. Creating topics with a thoughtful partition plan ensures parallel processing and balanced load. Proper partitioning reduces latency and prevents bottlenecks. This setup allows multiple consumers to process data efficiently. By planning, your platform can scale as traffic increases. A well-chosen broker and structured topics are crucial for throughput, reliability, and maintainability. It sets the foundation for building a resilient streaming system.
c. Producers Instrumented and Idempotent
- You instrument producers with OpenTelemetry to track events and monitor performance. Adding idempotence ensures duplicate messages do not break downstream systems. Instrumentation helps you detect issues like high latency or missing events. Idempotence protects your platform during retries or network failures. By combining observability with reliable message delivery, you maintain data integrity. This practice ensures that your real-time pipeline runs smoothly and produces accurate results even under stress or unexpected failures.
d. Stateful Processor with Durable State
- You deploy at least one stateful processor like Flink or Kafka Streams to handle event aggregation or joins. Durable state and checkpointing ensure that your system can recover after failures without losing data. Stateful processing allows calculations across windows, sessions, or aggregations. By using durable storage, you prevent inconsistencies when jobs restart. This setup ensures your real-time platform provides accurate, reliable insights even in high-volume workloads. It also improves the resilience and correctness of stream computations.
e. GitOps Configured for Manifests and RBAC
- You use GitOps tools like Argo CD to manage your manifests declaratively. Storing configuration in Git provides version control, auditability, and safer rollbacks. Configuring RBAC controls who can access or modify platform resources. GitOps ensures that your deployment is consistent across environments and reduces human errors. By automating updates and enforcing permissions, your streaming platform becomes more secure and reliable. It also speeds up development cycles while maintaining compliance and operational safety.
f. Observability Dashboards and Alerting
- You set up observability dashboards for metrics like consumer lag, throughput, and end-to-end latency. Alerting notifies you if performance drops or errors occur. By combining metrics, logs, and traces, you gain a complete picture of system health. Observability helps you identify bottlenecks, prevent downtime, and optimize performance. It also guides scaling decisions and troubleshooting. With proper dashboards and alerts, your real-time streaming platform becomes easier to monitor, maintain, and operate efficiently under heavy workloads.
g. Security: TLS, Auth, Schema Controls, Policy Enforcement
- You secure your pipeline with TLS for encrypted communication and authentication for service identity verification. Schema access controls prevent unauthorized changes to event formats. Enforcing policies as code ensures consistent security practices across the platform. These measures protect sensitive data and reduce risks from accidental or malicious access. By combining encryption, access control, and automated policy enforcement, you make your real-time streaming system resilient and trustworthy. Security ensures compliance and safe operation in production environments.
h. Disaster Recovery Plan
- You create a disaster recovery plan with replication, backups, and a replay runbook. This ensures that if brokers fail or partitions are lost, you can recover quickly. Backups protect historical data, while replay procedures restore processing state safely. DR planning reduces downtime and prevents data loss. By testing your plan regularly, you maintain confidence that your real-time platform will continue operating under failures. A well-prepared DR plan improves resilience and builds trust with users and stakeholders.
i. Load and Chaos Tests Passing
- You perform load testing to simulate realistic traffic and ensure your platform can handle peak demand. Chaos testing introduces failures like broker crashes or delayed consumers to validate resilience. These tests reveal bottlenecks and weak points before production. By passing both load and chaos tests, you ensure your real-time streaming system remains reliable under stress. Testing builds confidence, improves fault tolerance, and prepares your platform to handle unexpected scenarios safely.
18. Further reading & resources (shortlist)
- You need a list of resources to deepen your knowledge and stay updated on best practices. Books, blogs, and official documentation help you understand brokers, stream processing frameworks, and client transports. Tutorials and case studies provide real-world examples of real-time pipeline design and troubleshooting. By exploring curated materials, you can learn about scaling, security, observability, and CI/CD practices. Using these resources improves your skills, accelerates problem-solving, and ensures your streaming platform remains efficient, reliable, and aligned with modern industry standards.
a. Kafka vs Pulsar Deep Dives and Benchmarks
- You explore Kafka and Pulsar documentation and community benchmarks to understand their strengths and weaknesses. Comparing throughput, latency, and scalability helps you choose the right broker for your platform. Vendor docs show recommended configurations and features, while community articles provide real-world insights. By studying these resources, you can make informed decisions about partitioning, replication, and operational complexity. Understanding tradeoffs ensures your streaming system is efficient, reliable, and aligned with your project goals, while avoiding surprises in production workloads.
b. WebTransport IETF Drafts and WebRTC Articles
- You review WebTransport IETF drafts and WebRTC ecosystem articles to understand client-side streaming options. These resources explain low-latency, bidirectional communication and techniques for handling real-time media or telemetry. Tutorials and examples show how browsers and mobile devices implement these protocols. By following best practices, you can choose between WebRTC for media-heavy interactions and WebTransport for low-latency data channels. Learning from these resources helps you design responsive, interactive applications that meet modern real-time streaming requirements.
c. OpenTelemetry Project and Trend Articles
- You study the OpenTelemetry project and trend articles to improve your observability strategy. They show how to collect metrics, traces, and logs consistently across your streaming platform. Understanding sampling, adaptive telemetry, and integration with monitoring tools helps you detect latency or bottlenecks early. Community resources share best practices for dashboards, alerting, and correlation of events. By learning from these articles, you ensure your real-time pipeline is observable, maintainable, and capable of quickly identifying issues before they impact users.
d. CNCF/GitOps Resources on Argo CD and GitOps Adoption
- You explore CNCF and GitOps resources to learn how teams manage deployments declaratively. Argo CD and Flux examples show how to sync Git manifests, perform health checks, and enforce RBAC policies. Adoption stories explain the challenges and benefits of GitOps in production. By studying these materials, you understand how to implement safe rollbacks, versioned platform state, and automated CI/CD. These resources help you build a resilient streaming platform that is easier to operate and scales safely with growing workloads.
Conclusion
- In the fast-paced landscape of real-time systems, your greatest strength lies in building a unified platform, rather than selecting individual tools. This approach represents more than a technical choice; it is a strategic mindset. By combining a reliable broker, durable processing, and standardized telemetry with a GitOps-driven deployment pipeline, you lay the foundation for systems that are both scalable and resilient. You are no longer tied to fragmented solutions or manual configurations. Instead, you use managed services and community standards like OpenTelemetry and GitOps to move with confidence and speed.
- Whether you are scaling event-driven workloads or creating your first production pipeline, this roadmap helps you focus on what matters most: consistency, visibility, and automation. You are not just designing another streaming platform; you are defining how modern data infrastructure should operate in 2025 and beyond. With the right practices in place, you lead your team toward real-time systems that are reliable, adaptable, and ready for the future.