The rise of artificial intelligence (AI) and machine learning (ML) has changed the way industries operate, from transforming healthcare to reshaping finance. But here’s the challenge: while building AI models is exciting, deploying them into production is often a bottleneck. Traditional DevOps practices work great for software development but struggle with the unique demands of AI/ML workflows. This is where MLOps comes in—a powerful fusion of Machine Learning (ML) and DevOps.
In this blog, we’ll explore how MLOps transforms AI workflows by improving the deployment, monitoring, and automation of ML models. You’ll learn why integrating MLOps into your DevOps practices is a game-changer that accelerates AI project success. Get ready to understand how this revolutionary approach is setting the stage for the future of machine learning.
1. What is DevOps?
- DevOps helps you connect software development and IT operations by focusing on teamwork, automation, and continuous delivery. You and your team work together to build, test, and release software faster and more smoothly. With DevOps, you fix issues quickly, improve quality, and keep things running well from start to finish.
a. Automation
With automation, you use CI/CD pipelines to handle code integration, testing, and deployment automatically. Instead of doing everything by hand, the system checks and delivers your code for you. This helps you catch bugs faster, release updates quickly, and make fewer mistakes. It’s like having a robot assistant that builds and ships your software every time you make a change.
b. Infrastructure as Code (IaC)
- IaC means you control infrastructure (like servers and networks) using scripts instead of setting things up manually. You write and save these scripts in version control systems like Git. This way, you can reuse them, track changes, and fix issues easily. It’s like writing instructions for building your workspace so you can rebuild or update it anytime, just by running your code.
c. Monitoring
- Monitoring is when you track how your application is doing in real time. You keep an eye on things like speed, errors, and how users are interacting with it. This helps you spot problems before they grow and fix them quickly. It’s like watching your app’s health live so you can keep everything running smoothly for users.
Note:
- DevOps helps you speed up software delivery, but it doesn’t handle machine learning (ML) tasks very well. It doesn’t have built-in tools for things like data versioning, model training, or drift detection. That means you can’t easily track data changes, train ML models, or see when your model’s performance drops over time. If you’re working with ML, you need something more, like MLOps, to take care of those special tasks that DevOps doesn’t cover.
2. What is MLOps?
- MLOps is like an upgrade of DevOps made for machine learning (ML). It helps you manage the full ML lifecycle, from preparing data and training models to deploying and monitoring them. MLOps focuses on automation, teamwork, and version control for both code and data. It makes your ML projects easier to repeat, test, and improve. With MLOps, you can build smarter systems faster while keeping everything organized and running smoothly, just like DevOps, but for ML tasks.
a. Reproducibility
- Reproducibility means you can repeat your results exactly. You do this by versioning your data, models, and hyperparameters (the settings you use to train your model). That way, if something works well, you can go back and do it again, or fix things if they go wrong. It’s like saving every step of a science experiment so you or someone else can copy it and get the same results.
b. Scalability
- Scalability helps you work with large datasets and run distributed training on many computers at once. This is important when your data is too big for one machine or when training takes too long. MLOps tools help you handle this easily. It’s like having a team of computers working together to solve a problem faster, instead of making one computer do all the heavy lifting.
c. Monitoring
- Monitoring means you watch how your machine learning model works after it’s been deployed. You track things like how accurate it is and whether it’s affected by data drift, when new data is different from the data you trained on. If the model stops working well, you get alerts, or retrain it. It’s like checking a robot’s performance to make sure it keeps doing its job right in the real world.
Note:
- MLOps helps you move your machine learning models from experiments to real-world use smoothly and safely. Instead of just testing ideas, you turn them into working systems that people can use. With MLOps, you handle data, training, deployment, and monitoring in one process, so everything runs better and your models actually make a difference.
3. Why MLOps is Critical for AI Development
- AI projects come with special challenges that you need to handle. You work with huge datasets, and the models can be hard to train and explain. It’s also tricky to keep track of data changes and make sure your model stays accurate over time. Without the right tools, managing AI projects can be slow, messy, and unpredictable.
a. Data Complexity
- Your machine learning models depend on data, and that data keeps changing. As new data comes in, your model might not work the same way. This is called data complexity, and it means you have to keep updating and testing your model. If you don’t, it might make bad predictions. MLOps helps you handle this by making it easier to manage and track all those data changes over time.
b. Experimentation
- In AI, you try out lots of ideas to find what works best. You run hundreds of experiments by changing your models, settings, and data. It’s easy to lose track of what you did and what worked. MLOps helps you keep records of every version, so you can repeat good results or learn from mistakes. It’s like having a notebook for every experiment, all saved and organized.
c. Regulatory Compliance
- Some projects must follow rules and laws like GDPR to protect people’s data. This is called regulatory compliance. You need to show how your model made decisions and prove it was fair and safe. With MLOps, you can audit your models by saving all the details, like data, code, and results. That way, you stay legal, ethical, and trustworthy.
Note:
- Without MLOps, you and your team can run into big problems. Deployments become inconsistent, meaning your model might work in one place but not another. Your model can go stale if it’s not updated with new data. You also face compliance risks if you can’t track how your model makes decisions. MLOps helps you avoid all that.
4. Convergence of MLOps and DevOps
-
In DevOps, you work together with others to build and release software faster. It uses automation, collaboration, and continuous delivery to make sure your code is always tested and ready to go live. This helps you fix problems quickly and improve software quality. MLOps is like DevOps, but for machine learning. You use it to handle everything—from preparing data and training models to deploying and monitoring them. By using MLOps, you can keep your machine learning projects running smoothly and make updates faster, just like in DevOps. It’s all about working smarter and faster as a team.
a. End-to-End Workflow
- In DevOps, you work with software from start to finish. In MLOps, you do more—you also manage data and machine learning models. These are treated like “first-class citizens,” meaning they’re just as important as the code. You use tools to help with things like bringing in data, cleaning it up, training models, and making them available for others to use. This creates a unified pipeline, where everything works together. So, you’re not just coding—you’re handling data and models as part of the full process, all the way from start to deployment.
b. Unified Lifecycle
- In MLOps, you keep track of both code and data, including things like models and hyperparameters (the settings that shape how a model learns). You use versioning, which means you save every change. That way, you can always go back, repeat your steps, or show your work. This helps with reproducibility and makes things more organized. You can use tools like Git, MLflow, or DVC to track everything. It’s like keeping a detailed science lab notebook, but for your machine learning projects. This helps data science and engineering teams work better together.
c. Automation & CI/CD
- With MLOps, you use CI/CD pipelines (Continuous Integration and Continuous Delivery) to make your work automatic. Instead of doing everything by hand, these pipelines can test, train, and deploy your machine learning models. When your data changes or your code is updated, your system can retrain the model and send it out automatically, just like software updates in DevOps. This saves you time, avoids mistakes, and helps you get better results faster. It’s like setting up a smart machine that handles your model for you every time there’s something new.
d. Monitoring & Governance
- In DevOps, you check if your app is working well. In MLOps, you do the same, but also watch your machine learning models. You track things like accuracy, drift (when data changes), and bias (fairness). You also care about governance, which means following rules, ethics, and making sure your models are used the right way. If something goes wrong, your system can send alerts or retrain the model automatically. This keeps your models healthy, fair, and reliable, even after they’re deployed. It’s like giving your model a check-up while it’s out in the world.
Note:
- In summary, MLOps is when you take the best parts of DevOps and apply them to machine learning. Instead of building models messily or randomly, you use a disciplined, automated pipeline called CI/CD. This means every time you try a new idea or change something, it’s tested, saved (versioned), and deployed the right way. You can experiment faster and still keep everything organized and reliable. With MLOps, you deliver machine learning solutions more quickly, more safely, and with better teamwork. It helps you build smarter systems without losing control of your work.
5. Benefits of CI/CD in ML Workflows
-
When you build CI/CD pipelines for machine learning, you get lots of benefits. Your work becomes faster, more organized, and easier to repeat. You can test, train, and deploy models automatically, saving time and avoiding mistakes. It also helps you update models when data changes, so they stay accurate and reliable in the real world.
a. Faster Iteration and Delivery
- With automated pipelines, you can quickly make small updates to your machine learning models and code. This helps you test new ideas faster and get changes into the real world sooner. Instead of waiting weeks for big updates, you can send out smaller ones often. This lowers the risk of big problems and helps your model keep improving. It’s like building and updating your app in tiny steps instead of all at once.
b. Consistency and Reproducibility
- CI/CD pipelines help you keep things consistent every time you test and deploy. When you containerize your model using tools like Docker or Kubernetes, you make sure it runs the same way everywhere. You also track versions of your code, data, and models, so you can always go back and repeat exactly what worked. This makes your work more reliable and easier to explain or fix later.
c. Quality and Reliability
- Pipelines use automated tests to check your code, data, and model performance before anything goes live. These tests catch mistakes early, so bad models don’t reach your users. It’s like having a safety net that keeps your system from breaking. You can find and fix problems in a staging area before they go into production, which helps keep your work safe and trustworthy.
d. Collaboration and Transparency
- With CI/CD, every change you make—to code or data—goes through a shared process the whole team can see. This makes it easier to work together and follow best practices. Everyone can check what was changed, review updates, and know how things are built. It helps data science and engineering teams stay connected and builds trust in the final product.
e. Scalability and Automation
- Once you build your CI/CD pipeline, it can grow and handle more work without needing more people. You automate tasks like training, packaging, and deployment, so the system updates itself when new data comes in. For example, your model can automatically retrain and redeploy with fresh data. This is super useful because ML models need to stay accurate as the world around them changes.
Note:
- CI/CD pipelines make your machine learning work faster, safer, and easier to maintain. You and your team follow one automated process, so everyone stays on the same page. By making small updates, you lower the risk of big mistakes. Companies using CI/CD report better productivity and model quality, because things get done faster and with fewer errors.
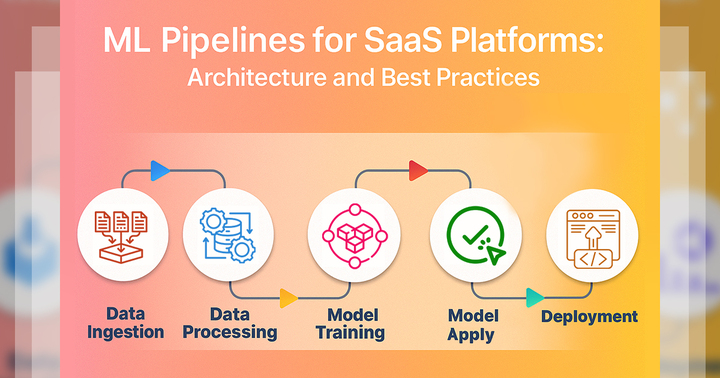
6. Building a CI/CD Pipeline for Machine Learning
-
A strong MLOps pipeline takes you step by step from development to production. Each stage uses smart tools and best practices to keep your work reliable and easy to scale. You don’t have to do everything manually—things like testing, training, and deployment are automated, so your models are always up-to-date and ready for real-world use.
Step 1: Version Control (Code, Data, and Models)
- You use tools like GitHub, GitLab, or Bitbucket to track changes in your code, data, and models. This is called version control. Tools like DVC or Git-LFS help you manage big files like datasets and model outputs. You can also use something like MLflow to keep a record of model versions. This way, every test you run can be reproduced, and you always know exactly what worked.
Key Actions
- When you commit changes to your code or data, it starts your CI pipeline to automatically test and build your project. You also tag model versions so it’s easy to go back to them later. Keeping your branches (like dev and prod) organized and using pull requests helps your team review changes carefully. This keeps your project clean, clear, and ready to grow.
Step 2: Automated Testing
- When you push code, tools like GitHub Actions, Jenkins, or GitLab CI automatically run tests. These check if your code logic works (unit tests), if the whole system works together (integration tests), and if your data is clean (data validation using tools like Great Expectations). For machine learning, you also test if your training script works and if the model hits a minimum performance on test data. This helps you catch problems right away.
Key Actions
- If any test fails—like your model doesn’t hit the required score or your data is bad—the whole pipeline stops. This keeps bad code or broken models from moving forward. It’s like having a guard at the door who only lets in the good stuff. Fixing problems early saves time and makes sure only the best code and models get deployed.
Step 3: Model Training (Pipeline CI)
- Now your CI pipeline builds and trains the model. You can use tools like Kubeflow, Argo Workflows, or cloud services to manage the steps. The system runs your training code on powerful machines like GPUs in the cloud. It also handles data prep and saves the final model. You don’t have to run things manually—everything is part of the automated pipeline, making training faster and more reliable.
Key Actions
- If needed, you can set the pipeline to try different hyperparameters, but usually you want the training to be predictable using a fixed setup. Always store logs and metrics from training so you can track results. Make sure everything runs in a container (like Docker) so it’s easy to reproduce. That way, your model will work the same way on any computer or cloud.
Step 4: Model Validation and Approval
- After your model is trained, the pipeline automatically checks if it’s good enough. It tests the model on new data it hasn’t seen before (called a holdout test set) and compares it to the current production model. This model checks metrics like accuracy, precision, or even real-world results. It also checks for data drift or bias. If the model passes all tests, it’s approved. If not, the system stops and alerts the team.
Key Actions
- The system compares your new model’s scores with the old one. For example, if new_accuracy < old_accuracy, the pipeline fails. This stops worse models from going live. You also save reports that show all the evaluation results. This step is important because it protects your users by making sure only equal or better models get deployed, not ones that make more mistakes or have issues.
Step 5: Containerization
- Now, you package your trained model and the code that runs it into a container using tools like Docker. A container is like a portable box that holds your code, libraries, and the model, so everything works the same, no matter where you run it. This makes your model super consistent from testing to production. So, whether you run it on your laptop or in the cloud, it behaves the same way every time.
Key Actions
- Your CI pipeline builds the Docker image and checks it for security issues. Then you push the image to a registry like DockerHub, AWS ECR, or Azure ACR. This image is what gets deployed to the real world. It’s like preparing a clean, sealed lunchbox that can be delivered anywhere and still work perfectly, making sure everything is neat, safe, and ready to go.
Step 6: Deployment
- Now it’s time to deploy your containerized model into the real world. You can use tools like Kubernetes, AWS SageMaker, or Google Vertex AI to launch your model. If you want it to answer questions right away, you expose it through an API. If it runs on big batches of data, you can schedule it to run regularly. Using smart deployment methods like blue/green releases helps you avoid downtime and keeps things running smoothly.
Key Actions
- You should automate the deployment using tools like GitOps, which push changes directly to your system (like a Kubernetes cluster). Or use cloud tools (like AWS CLI or SDKs) in your CI pipeline to create a new model endpoint. After deploying, always run smoke tests—quick checks to make sure the model is live and working. That way, you catch problems early and give users a smooth experience.
Step 7: Monitoring and Feedback Loop
- After your model goes live, you need to monitor it all the time. Watch system health like speed (latency) and errors using tools like Grafana or cloud monitors. More importantly, keep an eye on the data going into and out of your model. Use special tools like Fiddler or Seldon to spot drift or when your model’s performance drops. This helps you catch problems early, before users even notice them.
Key Actions
- You set up alerts for problems like lower accuracy, strange data changes, or slow response times. If something goes wrong, your pipeline can automatically retrain the model—this is called Continuous Training (CT). You also log predictions and actual results to see how the model is doing and to improve it over time. This feedback loop helps keep your model smart, fair, and ready for whatever comes next.
Note:
- This architecture creates a fully automated ML deployment process. By codifying each step, you ensure that your team can make consistent and repeatable releases of your model. Any code changes or new data automatically flow through the system, so updates reach production without needing manual work. Over time, this solid pipeline lets you experiment faster and scale AI solutions confidently, helping your team innovate and deliver more effective models.
7. Key MLOps Tools and Platforms
-
There are many tools and platforms that help you with each step of the MLOps pipeline. These tools make it easier to manage data, train models, and deploy them. Big companies use them to keep everything running smoothly. By learning these tools, you can build, test, and ship ML models faster and with more confidence.
7.1 CI/CD and Version Control
- You use tools like GitHub Actions, GitLab CI, or Jenkins to automate testing and building every time you update your code or data. This helps you catch mistakes early. Tools like DVC or LakeFS track versions of your datasets and models, just like Git tracks code. With MLflow, you can log models, check different versions, and make sure you always know which model did what.
7.2 Containerization & Orchestration
- You use Docker to package your model into a neat container, like putting it in a ready-to-go lunchbox. Then, tools like Kubernetes help you run and manage that container. With Kubeflow Pipelines, you can create a full flow for training and serving models, while Argo Workflows helps you automate complex steps. These tools orchestrate your ML work, making sure everything happens in the right order.
7.3 Experiment Tracking & Metadata
- Tools like MLflow, Weights & Biases, or Neptune.ai help you track experiments. Every time you try a new idea—different data, parameters, or models—these tools log what you did and what results you got. That way, you never lose track and can always repeat or improve past work. Tools like Pachyderm even track your data’s full history, making your work organized and trustworthy.
7.4 Model Serving
- Once your model is ready, you need a way to make predictions in real time. Tools like TensorFlow Serving or TorchServe help you do that. If you use Kubernetes, Seldon Core, or KFServing work great. Or you can use cloud platforms like AWS SageMaker, Google Vertex AI, or Azure ML to easily deploy and scale your model so it helps real users without slowing down.
7.5 Cloud-Native MLOps Services
a. AWS SageMaker:
- With AWS SageMaker, you get a full platform to train, deploy, and manage ML models—all without building everything from scratch. It now connects with MLflow, so you can easily track experiments. You also get AutoML, which helps you build models with less coding. It even has monitoring built in, so you know how your model is doing once it’s live. This service is great when you want one place for all your ML work.
b. GCP Vertex AI:
- Google Cloud’s Vertex AI gives you tools to train models, whether you write the code yourself or use AutoML to build it automatically. With Vertex Pipelines, you can set up a full CI/CD pipeline for your ML project. It also includes the Vertex Model Registry, where you can store and organize your models. Everything is in one place, helping you move fast and keep your ML process organized and scalable.
c. Azure Machine Learning:
- With Azure ML, you can create full ML pipelines, use MLOps templates, and even monitor your models after they’re deployed. It works really well with Git, so you can version your code and data. Azure ML also has its own tools for experiment tracking and model performance. You get a complete environment to build, test, and manage models, and everything is set up to support automation and teamwork.
7.6 Workflow and Data Tools
- You use Apache Airflow to build and schedule data pipelines, making sure your data flows through steps like cleaning and transformation. Argo CD helps you do GitOps deployments, meaning your code changes go live through Git. With Great Expectations, you can check your data quality to avoid surprises. Tools like Redis or Kafka work as feature stores, which means they store and deliver useful data features to your ML models super fast when they need them.
Below is a summary of MLOps tools by category:
| Pipeline Stage | Open-Source / CI Tools | Cloud / Managed Services |
|---|---|---|
| Version Control | Git + DVC, MLflow, Pachyderm | Azure Repos + MLflow support, SageMaker Experiments |
| CI/CD Pipelines | GitHub Actions, Jenkins, GitLab CI, Argo Workflows, Kubeflow Pipelines | AWS CodePipeline/SageMaker Pipelines, GCP Cloud Build + Vertex Pipelines, Azure DevOps/YAML Pipelines |
| Experiment Tracking | MLflow, Neptune.ai, Weights & Biases, Aim Stack | SageMaker Debugger, AzureML Logging, Vertex AI Experiments |
| Containerization | Docker, Podman | Docker (Amazon ECR, ACR) with managed Kubernetes (EKS, AKS, GKE) |
| Deployment Orchestration | Kubernetes, Kubeflow, Argo CD, Airflow | SageMaker Endpoints, Azure ML Endpoints, Vertex AI Prediction, AWS Lambda/Fargate |
| Monitoring & Observability | Prometheus, Grafana, Seldon Alibi, Fiddler, Monte Carlo (data) | AWS CloudWatch SageMaker, Azure Monitor, Google Cloud Monitoring |
Note:
- Each tool you use has pros and cons. GitHub Actions and Jenkins are great for regular CI/CD, and you can set them up for ML projects too. Argo Workflows and Kubeflow are better when you need to run complex ML pipelines on Kubernetes. MLflow helps you track experiments and manage models, and you can host it yourself or use Databricks. Tools like SageMaker or Vertex AI give you full ML pipelines without needing to manage the setup.
8. Open-Source vs. Managed MLOps Platforms
- When you pick tools for your MLOps setup, you choose between open-source tools and managed cloud services. Open-source gives you more freedom and control, but you have to set up and maintain everything yourself. Managed services like SageMaker or Vertex AI handle the hard parts for you, so they’re easier to use but might give you less control. You should pick what fits your project size, skills, and how much time you want to spend managing tools.
| Aspect | Open-Source MLOps Tools | Managed Cloud Services |
|---|---|---|
| Flexibility | Highly customizable; use any combo of tools | More opinionated; limited to provider’s offerings |
| Setup Effort | Requires assembly and maintenance of components | Quick start with out-of-box pipelines and UIs |
| Maintenance | Team handles updates, scaling, and security | The provider handles infrastructure, updates, and patching |
| Vendor Lock-in | Low – can move between clouds or on-premises | High–pipelines tied to the platform (but easier integration) |
| Cost | No licensing (but pay for infra); often free community support | Pay-as-you-go pricing may be costlier, but it includes support |
| Community & Support | Large open communities, but self-support | Enterprise support SLA, integrated with cloud ecosystem |
| Compliance/Security | Customizable to policies, but you configure everything | Provider offers built-in compliance certifications |
Note:
- If you want full control and know some DevOps, you can use open-source tools like Kubeflow, Argo, or MLflow. You can customize everything, but the setup takes a lot of time. If you prefer an easy setup, cloud platforms like SageMaker or Vertex AI give you one-click pipelines and auto-scaling. This saves time but might limit your choices and create vendor lock-in. For example, MLflow works fully if you host it yourself, but SageMaker supports it with some limits.
- A smart way to work with MLOps is to use a hybrid approach. You mix cloud tools for easy scaling and some open-source tools for flexibility. For example, you could train models on SageMaker, but use Kubeflow to handle custom data steps. Or use GitHub Actions to manage jobs both in the cloud and on your own servers. Your best setup depends on your team size, budget, and how much tech skill your team has.
9. Real-World MLOps Case Studies
-
Many companies now use DevOps-style pipelines for AI projects, and it really helps. You see faster model updates, better teamwork, and more reliable systems. Big names like Netflix, Airbnb, and Google use these setups to deliver ML models quickly and safely. You can learn from them and build your own smooth, automated ML workflow too.
9.1 Netflix – Metaflow:
- Netflix made Metaflow, a tool that helps you build and run ML pipelines using Python. It tracks your data, models, and code versions, so nothing gets lost. Netflix runs thousands of ML projects using it. You can move from a notebook to production fast, which makes your ML work smooth and quick
9.2 Uber – Michelangelo:
- Uber built Michelangelo, an ML platform that does everything—from handling data to training, evaluating, and deploying models. It’s so powerful that most ML at Uber goes through it. As a data scientist, you just click to deploy, while the MLOps team takes care of the hard setup, like CI/CD and servers.
9.3 Shopify:
- Shopify connects GitHub Actions, Terraform, and Kubernetes to create a full CI/CD pipeline for their ML models. This helps them manage feature engineering and deploy models easily. You could do the same—write code, push it to GitHub, and let automation handle the rest.
9.4 Airbnb-AIDE:
- Airbnb made a platform called AIDE that automates the training and deployment of ML models. It uses Argo Workflows behind the scenes, which helps schedule and manage different steps. You just define your steps, and AIDE runs them in the right order on the cloud, making things faster and easier.
Note:
- These examples show you that automated CI/CD for ML works well in big companies. The key idea is to build a repeatable process where every change in data or model goes through the same pipeline. You can use tools like Git, Jenkins, and Docker from DevOps, along with ML tools like Kubeflow, MLflow, or SageMaker. This helps you test, track, and deploy your models faster, with fewer mistakes and more confidence.
10. Challenges of CI/CD in ML Workflows
-
When you use CI/CD for machine learning, you face some unique challenges that go beyond normal DevOps. You have to deal with changing data, model performance, and experiment tracking. It’s not just about code—you must also version your data, test your models, and handle drift over time to keep things accurate and reliable.
10.1 Complex Data Dependencies
- In ML, you rely a lot on data, not just code. You must version your datasets so you know exactly which one you trained your model on. You also need data validation to catch bad or unexpected data. If you skip these, your model results won’t be reproducible, and it’s hard to trust or repeat your work.
10.2 Experiment Reproducibility
- When doing ML, you try out many different experiments, changing settings and algorithms. You need to track every run, including the code, parameters, and results. Without this, you can’t compare which model works best or go back to a previous version. This tracking makes sure your work is repeatable and reliable.
10.3 Testing Complexity
- Testing ML is harder than testing normal software. You still need unit tests, but also need to check data quality and model performance. For example, your model should pass tests for accuracy on a separate dataset. Creating all these ML-specific tests takes time, but it helps you avoid mistakes in production.
10.4 Long Training Times
- Some ML models take a long time—hours or days—to train. This makes it tough to include them in your CI/CD pipelines. You need good hardware and sometimes clever tricks like smaller batches or incremental training to save time. Still, these long training jobs can slow down your workflow a lot.
10.5 Infrastructure Complexity
- ML needs special infrastructure, like GPUs, big data storage, and orchestration tools. Setting all this up, especially on cloud or Kubernetes, can be tricky. You also need to make sure your environments match (like using the same versions of software and drivers), or things may break at different stages.
10.6 Monitoring & Drift
- Once your model is live, data can change, and your model might get worse over time (called drift). You must set up monitoring to watch for these problems and maybe even retrain your model automatically. Without this, your model could make bad predictions without anyone noticing.
10.7 Collaboration Between Teams
- MLOps means working together—you, the data scientists, DevOps engineers, and ML engineers. But these groups often speak different tech languages. You all need to agree on shared workflows, tools, and who’s in charge of what. This takes good communication and sometimes a shift in mindset, not just tech changes.
Note:
- In ML, CI/CD gets more complex. You don’t just manage code—you also need data versioning, experiment tracking, and model validation. These things require special tools and workflows. To handle it, you use automation for data pipelines, track model versions, and set up monitoring to catch problems. Experts say you should apply DevOps methods, but adjust them to fit ML needs. This makes sure your projects stay organized, reliable, and ready for production.
Conclusion
- In today’s world of AI, combining MLOps with DevOps is your ticket to building a powerful and future-proof CI/CD pipeline. This combination helps you deploy AI solutions faster, safer, and at a larger scale, all while reducing human error and boosting reliability. Think of it as the backbone of your AI-driven projects, allowing your team to focus on innovation instead of worrying about infrastructure and deployments.
- If you’re just starting out, don’t worry about building a complex system from day one. Begin by integrating version control and automation into your pipeline. This will give you a strong foundation to build on as your AI maturity grows. With tools like MLflow, Kubernetes, and Git, you can track your models, manage experiments, and easily scale as your needs evolve.
- As you grow your pipeline, you’ll see your deployment speed improve, your models will become more reliable, and your team will have a better time collaborating and iterating. By adopting a DevOps + MLOps strategy, you ensure that your AI initiatives are both scalable and sustainable for the long haul.
- Ready to build your AI pipeline? Explore tools like MLflow and Kubernetes, or contact us to get a personalized roadmap tailored to your unique needs!