The rise of AI and machine learning has completely changed how you build, scale, and deliver SaaS applications. What was once a simple cloud-based service is now becoming an intelligent, data-driven ecosystem that learns and adapts to user behaviour. As businesses compete to offer faster, smarter, and more personalized experiences, traditional SaaS models begin to show their limits. Manual workflows, slow updates, and one-size-fits-all designs can no longer meet user expectations in today’s dynamic digital world.
That is where ML pipelines for SaaS come in. They bring the power of continuous learning, automation, and real-time decision-making into your platform. By combining data ingestion, feature engineering, model training, and deployment into one connected system, you can create products that grow smarter with every user interaction. In this article, you will learn what ML pipelines are, why they matter for SaaS, the challenges they solve, real-world use cases, best practices, and how they are shaping the future of intelligent cloud applications.
1. What is Machine Learning (ML) & SaaS?
1.1 Machine Learning
- Machine Learning (ML) is a branch of artificial intelligence that helps computers learn from data without being directly programmed. You train a system using examples or patterns, and it starts making predictions or decisions on its own. For example, imagine you use Spotify to listen to music. Over time, Spotify’s ML system studies what songs you play, skip, or repeat. It notices your music taste patterns and creates a personalized playlist called “Discover Weekly.” You did not program it to know your favorites because it learned by analyzing your listening behavior. That is what ML does. It helps software improve automatically using data and experience instead of direct instructions from you.
a. Machine Learning Model (ML Model):
- An ML model is a computer program that learns patterns from data and uses them to make predictions or decisions. You can think of it like a student who studies examples to answer future questions correctly. For example, if you train a model with pictures of cats and dogs, it learns how to recognize each one. Once trained, it can predict whether a new picture shows a cat or a dog based on what it learned.
1.2 SaaS (Software as a Service)
- Software as a Service (SaaS) is a way for you to use software online instead of installing it on your computer. Think about Google Docs. You do not install any program because you just open it in your browser and start typing. All your files are saved in the cloud, and Google manages storage, updates, and security for you. You can even work with friends on the same document at the same time. That shows how SaaS lets you use powerful software online without worrying about installation or maintenance on your own device.
2. Why ML Pipelines Matter in a SaaS Context
2.1 The nature of SaaS data and usage
- In a SaaS platform, many customers, called tenants, use the same software through the internet. Each tenant may have different usage patterns and data types, such as web clicks, mobile activity, or API logs. This creates a large and continuous flow of data that changes every second. The system must process this information quickly to provide real-time results like personalized dashboards or recommendations. For example, on Netflix, millions of users watch different shows, and the platform instantly studies their behavior to suggest new movies or series. You can see how SaaS systems must handle huge, diverse, and constantly updating data to serve every user effectively.
2.2 Why ML pipelines (and not ad-hoc ML)
- When you create just one ML model and stop there, you face many problems. The model’s accuracy drops over time as new data changes, and you must update it again and again. Without an organized pipeline, it becomes hard to monitor, test, or reuse the model. You may also struggle with deployment and scaling when your data grows. An ML pipeline helps you automate, track, and improve every step, keeping your model reliable and efficient. If you just build one model in a corner and call it done, you’ll face these problems:
a. The model degrades as data drifts or customer usage changes
- An ML model slowly loses accuracy when the data changes over time. This is called data drift. For example, if you build a model that predicts online shopping trends and people suddenly start buying eco-friendly products, your model may give wrong predictions because it learned from old habits. You need to update or retrain the model regularly so it stays accurate and matches new customer behavior and real-world conditions.
b. Deployment becomes manual, fragile, and time-consuming
- When you do not use an ML pipeline, you have to deploy models manually every time there is an update. This can be slow and full of errors. For example, if you upload a model file incorrectly, your app might stop working. An automated ML pipeline handles deployment safely and quickly. It helps you test, update, and release new models with less effort and without breaking existing systems.
c. Monitoring, governance, and versioning become afterthoughts, and you lose visibility
- If you do not plan proper monitoring and version control, you will not know how your model is performing. For example, if accuracy drops, you might not notice until users complain. Governance means tracking what data and methods were used to train a model, while versioning means saving every version for future checks. Without these, you lose transparency and cannot fix problems or explain model decisions easily.
d. Multi-tenant scaling and model reuse get messy
- In a SaaS platform, many customers or tenants use the same system. If you try to manage one model for each tenant without an organized pipeline, it becomes confusing and hard to scale. For example, if you update one model, others may stop working. With a proper ML pipeline, you can reuse features and models safely, handle multiple customers at once, and make sure every tenant’s data stays separate and secure.
2.3 Specific requirements for SaaS ML pipelines
a. Tenant Aware Models or Shared Model Architecture
- In a SaaS platform, you can design your ML system so that each customer, called a tenant, has a separate model or shares one model with custom features. For example, if you build a sales prediction system, one tenant may sell clothes while another sells electronics. Each may need different patterns. A tenant-aware model lets you fine-tune results for each customer, while a shared model saves time and resources by using common data patterns for all tenants.
b. Data Isolation and Governance
- Data isolation means each tenant’s data is stored and processed separately so that one customer cannot access another’s information. Governance ensures the data is handled safely and follows privacy laws. For example, if you manage data for hospitals, patient records from one hospital must not mix with those from another. You must use secure storage, access controls, and audit trails to protect privacy and maintain customer trust in your SaaS platform.
c. Scalability and Latency
- Scalability means your ML pipeline can handle more users and data as your SaaS grows. Latency is the time it takes to make predictions or process data. For example, an online learning platform may need to update recommendations instantly when many students log in at once. A well-designed pipeline must manage both heavy workloads and fast responses by using cloud computing, parallel processing, and efficient data handling to keep performance smooth for all users.
d. Feature Reuse Across Tenants
- A feature store allows you to save and reuse engineered features that your models use. Instead of creating new features for every tenant, you can use shared ones to save time and ensure consistent results. For example, a “total monthly logins” feature can be useful for many tenants in a productivity app. Reusing features reduces cost, prevents errors, and helps you build faster and more reliable ML models across all customers in your SaaS platform.
e. Continuous Delivery of Models
- As your SaaS application collects new data, your models must stay updated and accurate. Continuous delivery means your ML pipeline automatically trains, tests, and deploys new versions whenever needed. For example, if customer behavior changes during a holiday season, your model can retrain to reflect new patterns. Using tools like CI, CD, and CT, you make sure your models are always fresh, improving decisions and user experience without manual updates.
f. Observability, Monitoring, and Reliability
- Observability means you can clearly see how your ML pipeline performs in real time. You monitor data quality, model accuracy, and system health to detect problems early. For example, if a tenant’s model gives wrong recommendations, monitoring tools can alert you before users complain. By tracking logs, data lineage, and deployment records, you ensure the system stays reliable. This helps you maintain customer trust and deliver consistent ML-driven performance in your SaaS platform.
3. High-Level Architecture of an ML Pipeline for SaaS
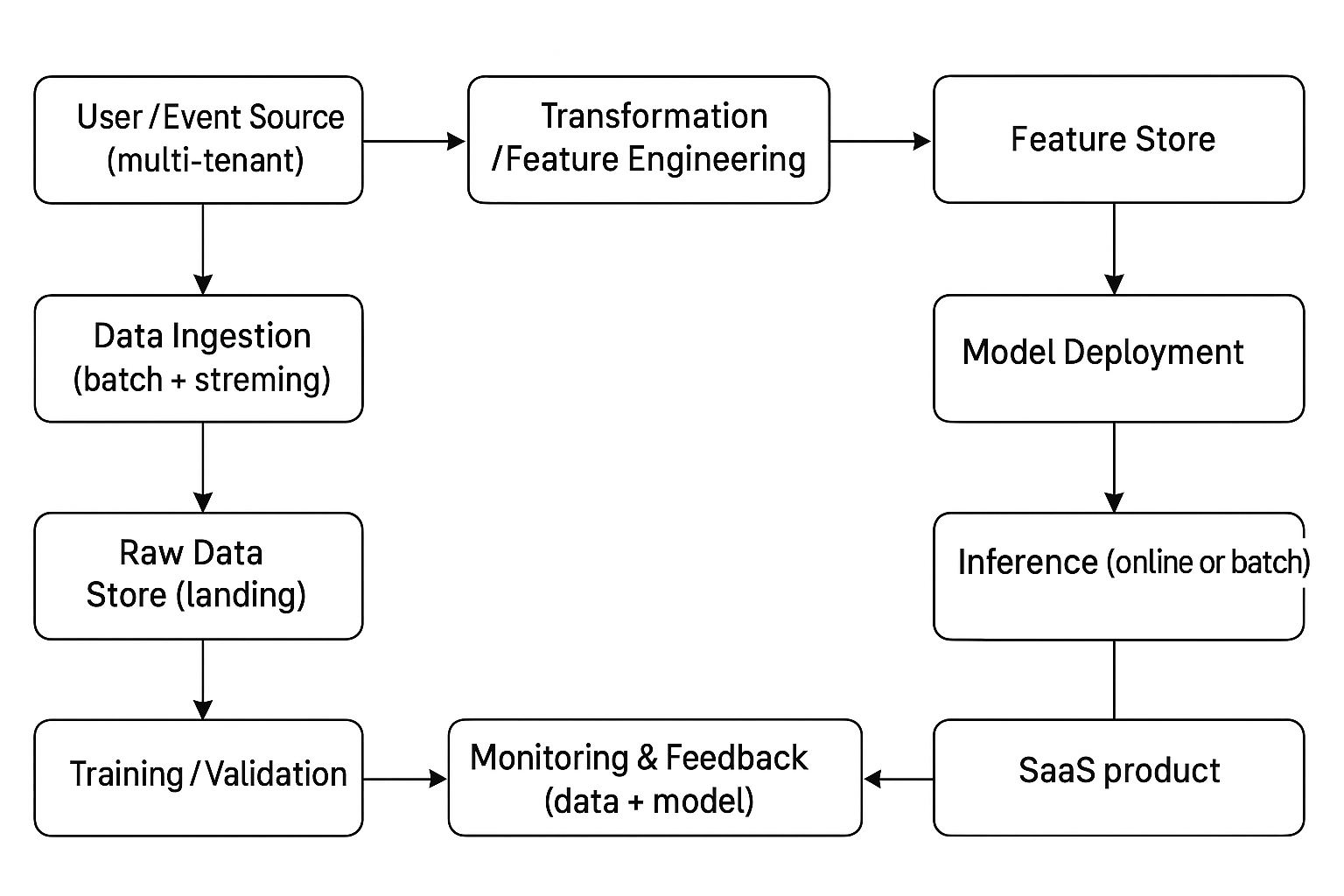
- The high-level architecture of an ML pipeline shows how data moves and transforms from start to finish inside a SaaS platform. It includes parts like data collection, storage, feature engineering, model training, deployment, and monitoring. You can think of it as a step-by-step path that turns raw data into smart predictions. By understanding this structure, you can build a system that is organized, scalable, and reliable for all your SaaS customers.
3.1 Layers/components
a. Data Ingestion or Collection
- Data ingestion is the first step in an ML pipeline where you collect data from many sources. This includes user activity, API logs, billing information, and even external data from partners. In a SaaS platform, you use special connectors and webhooks that understand which tenant the data belongs to. The system gathers both batch data that comes in groups and streaming data that arrives in real time. This ensures your ML models learn from complete and updated information. For example, a video streaming SaaS might gather data about what shows users watch and when they pause or stop. In a multi-tenant system, each tenant’s data is collected separately through APIs, webhooks, or batch uploads to keep everything organized and secure.
b. Data Storage and Feature Engineering
- After you collect data, you keep it in a data lake or data warehouse, which acts like a big digital library where all your information is safely stored and organized. This helps you easily find and prepare data for analysis. Then you do feature engineering, where you turn raw data into meaningful features that your ML model can understand. For example, from login records, you can create a feature like “average logins per week.” A feature store allows you to save, reuse, and update these features for both batch learning and real-time learning, making your models faster, more accurate, and consistent across different tenants in your SaaS platform.
c. Data Processing or Transformation
- In this step, you prepare the collected data so your ML model can use it effectively. You start by cleaning the data to remove errors or missing values, then normalizing it so all numbers follow the same scale. You also join data from different sources and enrich it with extra information. Finally, you label the data to show what each example means. For example, in a SaaS learning app, you may label students as “active” or “inactive.” In a multi-tenant system, you create tenant-specific transformations, such as usage levels for each customer, while also building global features that apply to all users. This process ensures your data is accurate, consistent, and ready for model training.
d. Model Training or Validation
- In this stage, you use your prepared data to train an ML model so it can learn patterns and make accurate predictions. You may build models for classification, regression, anomaly detection, or recommendations, depending on your goal. For example, a SaaS platform might train a recommendation model that suggests courses to students based on their learning history. After training, you perform validation to check how well the model works with new data. You can also run A or B testing by comparing two model versions to see which performs better. In a multi-tenant setup, you evaluate the model on different tenants to ensure it gives fair and reliable results for every customer using your SaaS application.
e. Monitoring or Feedback Loop
- After you deploy your model, you must monitor how well it performs in real situations. You track accuracy, data drift, response time, and cost to make sure everything runs smoothly. You also watch data quality and feature drift to see if the input data changes over time. For example, if a SaaS model predicts customer churn and suddenly performs worse, it may need updates. You then capture feedback such as new labels, user actions, or changes in customer behavior. This feedback is added to the next retraining cycle so the model learns from fresh data and stays accurate. Continuous monitoring helps your model stay reliable, adaptive, and valuable for every tenant using your SaaS platform.
f. Orchestration or Pipeline Automation
- Orchestration means managing and automating every step of your ML pipeline so that tasks run smoothly in the right order. You use workflow orchestration tools to connect processes like data ingestion, feature engineering, training, deployment, and monitoring into one continuous flow. For example, when new customer data arrives in your SaaS app, the system automatically cleans it, re-trains the model, and updates predictions. You also apply CI, CD, and CT practices for version control of data, features, and models, ensuring everything stays organized and reproducible. This automation reduces errors, saves time, and keeps your ML system running efficiently. With orchestration, your SaaS platform can continuously deliver accurate and updated results to users.
3.2 Architecture Diagram
3.3 Considerations for SaaS
- When you build an ML pipeline for a SaaS platform, you must think about how it handles multiple tenants or customers at the same time. Each tenant has unique data, usage patterns, and privacy needs. You must design the system so that it can separate, secure, and scale for all users efficiently. These considerations help your pipeline stay accurate, reliable, and cost-effective. By planning carefully, you can ensure your SaaS platform delivers personalized and consistent results for every customer.
a. Tenant Metadata Should Travel Through the Pipeline
- In a SaaS system, each customer or tenant has unique data. To manage this properly, every data point must carry a tenant identifier as it moves through the ML pipeline. This helps you track which data belongs to which tenant and allows you to analyze and evaluate models separately for each one. For example, in an online learning SaaS platform, tenant metadata helps you compare how models perform for different schools. It also ensures data stays organized, secure, and easy to filter. Keeping tenant metadata throughout the process makes the pipeline more transparent and prevents data from getting mixed between customers.
b. Model Versioning by Tenant
- When working with multiple tenants, you can create one global model for all users or add tenant-specific fine-tuning to improve accuracy. This means you start with a shared model that understands general patterns and then adjust it slightly for individual tenants. For example, a global recommendation model might work for most users, but a tenant selling electronics might need a small update to handle product-specific behavior. Keeping different model versions for each tenant helps track changes, compare performance, and maintain better control. It also ensures that each customer receives relevant predictions while you still save time and resources by reusing shared knowledge.
c. Feature Reuse
- Feature reuse means using the same engineered features across multiple tenants instead of creating new ones for each. Many tenants often share similar behavioral patterns, so you can design general features that apply to everyone. For example, a feature like “average login time per week” can be used by several companies using your SaaS product. By storing these in a feature store, you make them easy to access and update. This approach saves time, cost, and effort because you do not have to rebuild similar features repeatedly. It also keeps your models consistent, efficient, and faster to train across all tenants.
d. Latency vs Cost
- When managing an ML pipeline, you must balance latency and cost. Latency refers to how quickly a model provides results, while cost relates to the resources used for computing. For example, a fraud detection model in a payment SaaS must act instantly, which requires low latency and more computing power. On the other hand, a customer satisfaction model can be retrained once a day, saving cost. You need to decide which tasks require real-time scoring and which can run on scheduled retraining. By balancing both, you ensure that your SaaS application remains responsive, affordable, and efficient without overusing resources.
e. Data Governance and Compliance
- Data governance means managing data securely and responsibly, while compliance ensures you follow laws and regulations about privacy and storage. In a multi-tenant SaaS system, you must protect each tenant’s data using encryption, access control, and data isolation. For example, a healthcare SaaS storing patient data must keep records separate for each clinic and comply with privacy regulations. Some tenants may also have data residency requirements, meaning their data must stay in a specific country. By following strong governance rules, you protect user trust and maintain legal safety while keeping your ML pipeline secure and transparent for every tenant.
f. Scalability
- Scalability means your ML pipeline can handle growth in both data size and tenant count without losing performance. As your SaaS platform grows, hundreds or even thousands of customers may start using it, and each one will generate large amounts of data. For example, if your SaaS serves e-commerce companies, every store’s transactions will add up quickly. A scalable system uses cloud computing and distributed processing to manage this increasing load efficiently. It ensures that your model continues to train, predict, and update smoothly even as usage grows. Building for scalability keeps your SaaS application fast, reliable, and ready for expansion in the future.
4. Best Practices for ML Pipelines in SaaS
- When you create an ML pipeline for a SaaS platform, following the right best practices helps you build a system that is efficient, secure, and easy to maintain. These practices guide you in handling data, training models, and deploying updates smoothly. You learn how to keep your pipeline automated, scalable, and reliable while reducing errors and costs. By applying these proven methods, you can make your SaaS product smarter, faster, and more dependable for every customer.
4.1 Automate everything: CI/CD/CT for ML
- In modern machine learning operations, automation is the most important factor for success. When you try to manage everything manually, it becomes slow, difficult, and full of mistakes. By using CI, CD, and CT, which mean continuous integration, continuous delivery, and continuous training, you make your ML pipeline faster and more reliable. Automation helps you test, deploy, and update models quickly, keeping them accurate and efficient while saving both time and effort in your SaaS platform.
a. Version Data, Features, and Models
- You must version your data, features, and models to keep track of every change in your ML pipeline. This means saving different versions each time you update something so you can always return to a previous state if needed. For example, if a new version of your model performs poorly, you can go back to the older one. Versioning helps you maintain organization, reliability, and transparency, making your ML process easier to manage and debug.
b. Automate Training When New Data Arrives
- When new data enters your system, your model should retrain automatically so it always learns from the latest information. This process is called continuous training. For example, if you run a SaaS platform that predicts customer churn, new customer behavior data will improve your model’s accuracy. By automating training, you ensure your model stays updated, adaptive, and accurate without needing constant manual effort, which makes your ML pipeline more efficient.
c. Automate Testing
- You should set up automated testing to check your data and models regularly. This includes data quality checks to find missing or incorrect data, label sanity checks to confirm correct outputs, and performance tests to measure accuracy. For example, before deploying a new model version, automatic tests can confirm that it performs better than the old one. Automated testing helps you catch mistakes early, keep your data reliable, and make sure your SaaS models stay trustworthy and consistent.
d. Automate Deployment and Rollback
- You can use automation to deploy new models and roll back to older versions if problems occur. This helps you manage shared models or tenant-specific models without manual updates. For example, if a new version causes errors, the system can quickly restore the previous one automatically. Automated deployment ensures your models reach users smoothly and safely. It also saves time, reduces risk, and keeps your SaaS platform running without interruptions during updates or maintenance.
e. Use Feature Drift Detection and Trigger Retraining
- Feature drift detection helps you notice when input data starts changing over time, which can make your model less accurate. For example, if customer preferences shift suddenly, the model may begin predicting incorrectly. By detecting this drift early, you can trigger automatic retraining to refresh the model with new data. This process keeps your ML system accurate and relevant. Regular drift detection ensures your SaaS models continue to make smart and up-to-date decisions for all tenants.
4.2 Modular, reusable pipeline components
- When you design your ML pipeline, it is important to build it using modular components that you can easily reuse. Each part of the pipeline, such as data ingestion, transformation, feature engineering, training, and deployment, should work independently yet connect smoothly. For example, if you improve the transformation step, you can apply that change to all tenants without rebuilding the entire pipeline. You should also make the pipeline idempotent, meaning it gives the same results every time it runs, even if repeated. This avoids duplicate data and keeps your system clean. A modular and idempotent design helps you save time, reduce errors, and maintain a stable and efficient SaaS ML system for all users.
4.3 Data quality, observability, lineage
- To build a reliable ML pipeline, you must ensure strong data quality, observability, and lineage tracking. Data lineage helps you trace where each feature came from, which transformation created it, and what raw data source was used. For example, if your model predicts wrong results, you can follow the lineage to find and fix the issue. You should perform data quality checks to detect missing values, outliers, or inconsistent formats before using the data. Observability means monitoring your pipeline’s performance by checking latency, throughput, and success or failure rates. You also need to log model behavior, such as predictions, confidence levels, and input feature patterns. Together, these practices keep your SaaS ML system accurate, transparent, and trustworthy.
4.4 Scalability and Performance in Batch and Real Time
- In a SaaS platform, your ML pipeline must handle both batch processing and real-time processing depending on tenant needs. Batch processing means running models at scheduled times, such as every night, which is useful for generating reports or updating recommendations for many tenants at once. Real-time processing means giving instant results, which is important for high-value tenants, such as those needing quick fraud detection. You should define latency expectations, since not every prediction must happen instantly. For example, product recommendations can update hourly, but fraud alerts must appear in seconds. You also need to optimize costs by managing storage, computing power, and data transfer efficiently. Balancing scalability and performance keeps your SaaS system fast, affordable, and reliable.
4.5 Multi-Tenant Design and Tenant Isolation
- In a multi-tenant SaaS system, you must carefully separate each customer’s data to keep it secure and organized. This is done by maintaining metadata that identifies which data belongs to which tenant. You can use either a shared model, where one model serves all tenants, or a per-tenant model, where each customer gets a personalized version. For example, a marketing SaaS might use a shared model for small clients but a specialized one for a large enterprise. You must also maintain fair and transparent data usage, especially if data from multiple tenants is combined. Strong data governance is essential because you may need to show each tenant what data you use and how your ML models make predictions or decisions.
4.6 Feature Store and Reuse
- A feature store is a central place where you keep all the engineered features used by your ML models. It acts like a library that stores features in an organized and versioned way so both training and serving pipelines can access them easily. For example, you can store a feature such as “average time spent on the app per week” and reuse it for different models. This approach avoids duplication and ensures consistency across tenants. You can also maintain both batch features, such as daily activity summaries, and real-time features, like user actions from the last few minutes. Using a feature store helps you save time, improve accuracy, and make your SaaS ML pipeline more efficient and reliable.
4.7 Monitoring and Feedback Loop for Model Decay
- Over time, your ML model may lose accuracy because of data drift or concept drift, which means the data or patterns it learned from have changed. To prevent this, you must monitor model performance regularly by checking business metrics and evaluating results on hold-out data sets. For example, if a sales prediction model in your SaaS platform starts giving wrong forecasts after a market change, you can detect the drift and retrain it. You should also use model explainability tools to understand how predictions are made and to ensure fairness for all tenants. Continuous feedback loops help your model stay updated, unbiased, and reliable, ensuring that your SaaS application always delivers accurate and trustworthy results.
4.8 Governance, Security, and Compliance
- In a multi-tenant SaaS platform, you must protect every tenant’s data through strong governance, security, and compliance practices. Governance means setting clear rules for data access and usage. You should use encryption to keep information safe and maintain audit trails to track who accessed or changed data. For example, in a healthcare SaaS system, patient records must remain private and traceable. In regulated industries like finance or healthcare, you may also need to show the model version, feature lineage, and the reasoning behind each prediction for legal transparency. Maintaining reproducibility is equally important because you must be able to recreate any model version trained on specific data. These practices ensure your ML pipeline remains secure, fair, and trustworthy.
4.9 Cost-Conscious Design
- When you build an ML pipeline for a SaaS platform, you must focus on keeping it cost-efficient. Many teams waste money because of tool sprawl, which means using too many separate tools that make the system complex and expensive. Instead, you should use shared infrastructure whenever possible and allow your computing power to scale elastically based on demand. For example, if data usage increases during peak hours, the system can automatically expand, then shrink later to save cost. You should also manage data storage efficiently by keeping less-used data in cold storage and frequently used data in hot storage. Avoid unnecessary data movement, as it consumes time and resources. A cost-conscious design keeps your ML system efficient and sustainable.
4.10 Start Simple and Evolve Architecture
- When you begin building an ML pipeline for your SaaS platform, it is better to start simple instead of making it overly complex. At first, you may not fully understand your tenant use cases or what kind of models they truly need. For example, if you build a recommendation system, begin with a basic model that suggests popular items instead of creating a complicated real-time system immediately. Once you test it and gather feedback, you can slowly add new features, improve accuracy, and make the system more advanced. This approach saves time, reduces confusion, and helps you learn what actually works. By evolving your architecture step by step, you create a more efficient and flexible ML pipeline.
5. Real-World Application Scenario: Personalized Recommendation in a SaaS Platform
- In this scenario, you will learn how a SaaS company can use machine learning to create a personalized recommendation system. Imagine a platform that helps businesses manage their digital content and wants to suggest the right articles or videos to each user. By adding a recommendation engine, you can improve user engagement and customer retention. This example shows how an ML pipeline works in a real situation, helping every tenant deliver smarter and more relevant content.
5.1 Business Objectives & Use Cases
- The main goal of this SaaS platform is to use machine learning to show each user personalized content recommendations, such as articles, videos, or documents. These recommendations are based on each user’s behaviour, like what they read, watch, or click on. For example, if a user often views technology articles, the system will suggest similar topics next time. You can measure success through metrics like click-through rate, time spent on a page, and reduced customer churn. Since the platform serves many tenants, it must handle growth from a few clients to hundreds while reusing the same infrastructure. At the same time, it should allow customization for each tenant to meet their specific business needs effectively.
5.2 Real World SaaS Applications That Use Machine Learning Pipelines
a. Netflix (Personalized Recommendations)
- Netflix is a global SaaS platform that uses machine learning pipelines to recommend movies and shows. It collects user data such as watch time, clicks, and ratings through data ingestion. These are turned into features like viewing habits and genre preferences. Models are trained daily to predict what users will enjoy next. The system uses real-time inference when you open the app and shows suggestions instantly. Monitoring ensures recommendations stay accurate as user tastes change.
b. Salesforce (Customer Relationship Management)
- Salesforce uses ML pipelines in its Einstein AI feature to help businesses predict customer behaviour. It gathers customer interactions, emails, and sales records as data inputs. The data goes through transformation and feature engineering to build meaningful features such as deal probability or engagement rate. The model is trained and validated regularly to suggest the best leads to contact. Through automation and monitoring, Salesforce ensures that insights stay accurate for thousands of tenants worldwide.
c. Spotify (Music Personalization)
- Spotify uses machine learning to personalize playlists like “Discover Weekly.” It collects listening history, likes, and skips through data ingestion. These data points are turned into features such as favourite artists or preferred genres. Models are trained weekly to predict what songs each listener might like. Deployment happens in real time when you open the app, and feedback loops collect new listening data to retrain models. This continuous cycle keeps your playlists fresh and accurate.
d. Amazon (Product Recommendations)
- Amazon applies ML pipelines to power its recommendation system. It gathers massive amounts of purchase data, search queries, and browsing patterns. The system performs feature engineering to understand product relationships and customer preferences. Models are trained and retrained to recommend items like “Frequently Bought Together.” Monitoring and feedback help detect when user interests change, ensuring recommendations stay relevant. The system handles millions of tenants and users with strong data governance and scalability.
e. HubSpot (Marketing Automation)
- HubSpot uses machine learning in its CRM platform to help businesses improve marketing campaigns. It collects email interactions, ad clicks, and user engagement data from multiple sources. Through data transformation, it builds features such as engagement score or best time to send emails. Models are trained to predict which leads are most likely to convert. Automated deployment and orchestration tools update these models regularly. Monitoring ensures predictions stay correct as new campaign data arrives.
e. LinkedIn (Job and Connection Recommendations)
- LinkedIn uses ML pipelines to suggest jobs, people, and content. It ingests profile data, search history, and interaction logs from millions of users. It performs feature engineering to identify skills, interests, and industry trends. Models are trained on these features to recommend relevant opportunities. For example, if you engage with AI posts, LinkedIn suggests similar content. Continuous monitoring tracks engagement and re-trains models when interests shift, keeping recommendations both personalized and current.
f. Shopify (E-commerce Insights)
- Shopify uses ML pipelines to support its e-commerce merchants. It collects sales transactions, inventory data, and customer activity for each tenant. It builds features like average order value or peak shopping times. Models are trained to predict trends such as which products will sell next week. Deployment allows real-time updates to dashboards, and feedback loops use new data for retraining. Shopify also uses data governance to keep each merchant’s information private and secure.
4.3 Special SaaS Considerations
a. Tenant Onboarding
- When a new tenant joins your SaaS platform, there might be very little historical data to train a custom model. In that case, you can start using a global model that already understands general patterns. After about thirty to sixty days, once enough tenant data is collected, you can switch to a fine-tuned model designed for that tenant. This approach gives accurate results faster and ensures new tenants receive personalized recommendations without waiting for long data collection periods.
b. Cold Start
- A cold start happens when new users join a tenant, and the system does not yet know their preferences. To handle this, you can use tenant-wide features such as the most popular or trending content. For example, when a new student joins an online learning platform, the system can recommend the most viewed courses first. As the user interacts more, the model learns their behavior and provides personalized suggestions automatically over time.
c. Feature Sharing and Isolation
- In a multi-tenant system, some features like global content popularity can be shared among tenants, while others must remain tenant-specific for privacy. The feature store should carefully track each tenant’s data using tenant IDs and ensure proper isolation so that no data overlaps. For example, a global feature might show general trends, but tenant-specific data stays private. This approach keeps information secure, allows fair feature use, and maintains clear boundaries between customers.
d. Model Fairness and Bias
- Some tenants may have smaller or more unique user groups, which can cause the ML model to perform less accurately for them. To prevent this, you should regularly monitor model performance for each tenant. For example, if one tenant’s users receive poor recommendations compared to others, the model may need adjustments. Ensuring fairness keeps results consistent across all customers and avoids bias. This helps every tenant feel equally supported and improves overall system trust and reliability.
e. Cost Management
- In large SaaS systems, some tenants produce a huge amount of data and events, which can increase operational costs. To manage this, you can use data sampling, summarization, or selective real-time processing. For example, instead of processing every user click, you can process summarized data daily. This reduces resource usage while keeping the model accurate. Good cost management ensures your ML pipeline stays efficient, affordable, and scalable, even as more tenants and data are added to the system.
f. Compliance and Data Governance
- Different tenants may have special data privacy requirements, such as storing data in a specific region or preventing data sharing. Your ML system must follow these rules by using regional data partitions, encryption, and secure access controls. For example, a healthcare tenant may require patient data to stay within a certain country. By maintaining strong compliance and data governance, you protect customer trust, meet legal standards, and ensure that every tenant’s data remains safe and properly managed.
5.4 Example of Business Impact
- After deploying the machine learning pipeline, your SaaS platform can achieve strong business improvements. Tenants may see a 15% increase in click-through rate on recommended items and a 7% improvement in user retention within thirty days. The system becomes scalable enough to onboard 50 new tenants in the first year without needing major changes. By reusing features, you save about 30% of engineering time compared to building individual pipelines for each tenant. Continuous monitoring also detects when major content trends shift, such as a new video format becoming popular, and automatically triggers retraining. This quick response helps maintain high model accuracy and keeps user engagement consistent across all tenants.
6. Common Pitfalls and How to Avoid Them
6.1 Building a One-Off ML Proof but Not a Pipeline
- This issue occurs when you build a machine learning model as a quick experiment instead of making it part of a complete product pipeline. Many teams test a model once to prove it works, but never plan how to use it continuously in real life. Without a proper pipeline, the model cannot be updated, monitored, or scaled for more users. For example, if your model predicts sales once and stops learning from new data, its accuracy will quickly drop. You must treat ML as a long-term system, not just a single project.
Mitigation:
- To fix this problem, you should start with a pipeline mindset from the very beginning. This means treating your ML model as part of a real product, not just an experiment. You should build it like software code that can be deployed, tested, and improved continuously. By designing a full ML pipeline, you can easily manage data, automate training, and update models when needed. This approach helps your system stay reliable, scalable, and ready for real-world use.
6.2 Ignoring Data Drift or Model Decay
- This issue occurs when your machine learning model slowly becomes less accurate because the data changes over time. This change is called data drift, and it happens when user behaviour or business trends shift after the model is launched. For example, if your model predicts shopping habits based on last year’s data, it may fail when new products or customer preferences appear. When you ignore these changes, your model begins to decay, meaning it produces weaker results. To prevent this, you must monitor data patterns regularly and retrain your model whenever performance starts to drop.
Mitigation:
- You should create a monitoring system to track how your ML model performs after deployment. Use drift detection to notice when data or user behaviour changes, which can reduce accuracy. For example, if users start preferring new products, your model might give outdated recommendations. A feedback loop collects new information from users and sends it back for retraining. These steps help your model stay accurate, adaptive, and reliable as real-world conditions change over time.
6.3 Over Customising per Tenant Too Early
- This issue occurs when you start creating too many custom models or features for each tenant before fully understanding their actual needs. Doing this makes your ML system harder to maintain because every tenant will need separate updates, testing, and monitoring. For example, if you build ten different models for ten clients, you will spend too much time fixing and retraining each one. Instead, you should begin with a shared global model that works for everyone and add customization gradually when necessary. This approach keeps your SaaS pipeline simpler, more efficient, and easier to scale as your business grows.
Mitigation:
- When you begin creating your ML system, it is smart to start with a shared model that works for all tenants. This approach saves time, reduces cost, and helps you test how well the model performs across different users. Once you understand your tenants’ unique needs and gather enough data, you can build tenant-specific models for those who require customized results. This balanced strategy keeps your SaaS platform efficient, flexible, and easy to maintain.
6.4 Poor Feature Reuse
- This issue occurs when you do not reuse features across tenants and instead create new ones for every project. It leads to duplicate work, wasted time, and inconsistent results. For example, if you build the same “average login time” feature separately for ten tenants, you spend unnecessary effort repeating the same task. Without a shared feature store, your ML pipeline becomes harder to maintain and scale. To fix this, design reusable feature engineering components so all tenants can share common features safely, saving both time and resources while keeping your SaaS platform consistent and efficient.
Mitigation:
- You can solve this problem by creating a feature store that saves and manages all your important features in one place. This allows you to reuse features across multiple tenants without repeating the same work. By using modular feature engineering, you build small, reusable parts that can be easily combined for different models. For example, one feature that measures user activity can be shared across several tenants, helping you save time and maintain accuracy and consistency.
6.5 Lack of Observability and Lineage
- This issue happens when your ML pipeline does not have proper observability or data lineage tracking. Without these, it becomes very difficult to find the cause of problems when something goes wrong. For example, if your model starts giving incorrect predictions, you may not know which data or transformation caused the error. Observability helps you monitor the pipeline’s performance, while lineage shows where each piece of data came from. When both are missing, debugging takes longer, and mistakes can spread unnoticed. Tracking these elements ensures your SaaS pipeline stays transparent, reliable, and easy to maintain.
Mitigation:
- To make your ML pipeline reliable, you should create strong data lineage, logging, dashboards, and service level agreements (SLAs). Data lineage helps you trace where your data came from and how it was transformed. Logging records every action in the system so you can find errors easily. Dashboards give you a clear view of performance and health. SLAs define expected results and response times. Together, these tools make your pipeline transparent, accountable, and easy to maintain.
6.6 Ignoring SaaS Scale
- This issue arises when you do not design your ML architecture to handle the growing number of tenants, large data volumes, or the need for data isolation. At first, your system may work well for a few customers, but as more tenants join, it can become slow or even fail. For example, if each tenant generates millions of data records daily, your model might crash or give errors. To prevent this, you must plan for scalability from the beginning by using cloud infrastructure, efficient storage, and strong data separation for every tenant.
Mitigation:
- You should design your ML pipeline to be multi-tenant aware from the very beginning. This means using metadata to identify which data belongs to each tenant, setting up tenant routing to send requests to the correct model, and applying quotas to control how much each tenant can use the system. For example, if one tenant sends too many requests, quotas prevent system overload. This approach keeps your SaaS platform organized, fair, and scalable for all users.
6.7 Tool Sprawl and Cost Blow Up
- This issue happens when you use too many different tools for each step of your machine learning pipeline. Each tool may handle a small task like data cleaning, feature storage, or monitoring, but managing them all together becomes complicated and expensive. For example, if you use separate tools for every tenant, costs can rise quickly, and your team may struggle to keep them updated. Too many disconnected tools also make the system harder to monitor. To prevent this, choose integrated and scalable solutions that handle multiple tasks efficiently, keeping your SaaS ML pipeline simple, organized, and cost-effective.
Mitigation:
- This mitigation means you should simplify your technology stack by using fewer but more versatile tools. When you rely on too many separate platforms, your ML pipeline becomes complicated and harder to manage. By choosing modular yet unified tools, you keep each part flexible while ensuring they all work together smoothly. For example, using one platform for data ingestion, processing, and monitoring makes your system faster, easier to maintain, and more cost-efficient for your SaaS platform.
6.8 Security and Compliance Oversight
- This issue happens when your ML model or system does not follow proper security and data protection rules. If you ignore compliance, your model might accidentally leak sensitive data or break important privacy regulations. For example, a model trained on multiple tenants’ data could expose one company’s information to another if not properly isolated. This can lead to loss of trust and even legal problems. To prevent this, always use data encryption, access control, and audit checks. Following strong compliance standards keeps your SaaS platform safe, trustworthy, and legally protected at all times.
Mitigation:
- You should include strong data governance practices from the very beginning to keep your SaaS platform secure and trustworthy. This means setting clear access controls so only authorized people can view or edit data. You also need to use encryption to protect sensitive information and maintain audit logs to track who accessed what and when. Starting early with these steps helps prevent data misuse and builds trust and compliance for all tenants using your system.
7. Future Trends and Considerations
7.1 Real-time/streaming ML pipelines
- In the future, more SaaS platforms will move from slow batch processing to real-time ML pipelines. This means predictions will happen instantly as data flows in, such as click streams or live notifications. For example, a shopping app could recommend products the moment a user clicks on an item. To support this, you must design event-driven architectures that handle continuous data updates, use streaming frameworks, and process information quickly to keep the system responsive and accurate.
7.2 Democratizing ML Inside the SaaS
- As more non-ML engineers start using machine learning, your pipeline must become easier for everyone to access. You should build self-service tools that allow teams to experiment with features, train models, and deploy safely without deep coding skills. For example, a marketing team could test a new recommendation model directly. Thinking with a data products mindset helps make features and models reusable within your platform, improving collaboration, creativity, and faster innovation for your SaaS users.
7.3 Multi-tenant model orchestration & federated learning
- Some tenants require strict privacy, so you may use federated learning, which allows model training on local tenant data without sharing it. The system learns patterns from all tenants collectively while keeping their data private. For example, hospitals can train a shared medical model without exposing patient data. As the number of tenants grows, model orchestration becomes more complex, requiring strong coordination between different tenant-specific pipelines to ensure accurate training, scalability, and secure data management across your SaaS platform.
7.4 Explainability, fairness, regulation
- As machine learning becomes a key part of SaaS platforms, customers and regulators will demand more transparency. They will want to know how a model makes decisions and whether it is fair to all users. For example, if your model recommends jobs, it must not favour one group over another. To handle this, your pipeline should include explainability tools, audit logs, and fairness checks. These ensure your models stay ethical, unbiased, and fully compliant with data protection laws and standards.
7.5 Feature stores, model marketplaces
- In the future, many SaaS platforms will create internal feature stores and model marketplaces. These act as organized libraries where teams can find and reuse existing features and models instead of rebuilding them. For example, one team can use a proven “user engagement” feature created by another. This approach promotes modularity, reduces engineering time, and improves consistency. Having reusable ML assets encourages collaboration and helps you deliver smarter and faster solutions across all products within your SaaS ecosystem.
8. Summary
8.1 Importance of ML Pipelines for SaaS
- Machine learning pipelines are very important for SaaS platforms that want to add intelligence and automation on a large scale. They help process massive amounts of data smoothly and deliver accurate insights to users. For example, a content platform can use ML pipelines to recommend videos instantly. By using well-structured pipelines, you make your SaaS system more efficient, adaptive, and scalable, allowing it to grow with more users and deliver better, smarter experiences every day.
8.2 ML Pipeline Architecture
- A complete ML pipeline architecture includes many connected steps that move data from raw input to real results. These steps are data ingestion, storage, transformation, feature engineering, model training, deployment, monitoring, and feedback. Each step plays a key role in creating accurate predictions and keeping the model updated. For example, if one part fails, the rest of the process suffers. A good architecture ensures smooth automation, faster updates, and consistent outcomes for your SaaS platform.
8.3 SaaS Challenges in ML Pipelines
- When you build an ML pipeline for a SaaS platform, you face special challenges such as multi-tenant design, scalability, latency, data governance, and cost management. Each tenant produces its own data and may need separate processing. For example, a small business and a large enterprise will use the same platform differently. You must balance performance, privacy, and cost while keeping everything secure and fast. Handling these challenges well makes your SaaS system reliable and efficient for every customer.
8.4 Best Practices for ML Pipelines
- To build an effective ML pipeline, you should follow some key best practices. These include using automation through CI, CD, and CT, designing modular components, improving observability, and promoting feature reuse. You must also monitor for data drift, apply strong governance, manage costs wisely, and start simple before adding complexity. For example, testing small updates before scaling prevents errors. Following these practices helps you create a pipeline that is efficient, secure, and easy to maintain.
8.5 Real World Scenario Example
- A great example of ML in SaaS is a personalized recommendation system. In this setup, users get customized suggestions based on their activity, such as videos, products, or articles. For instance, a SaaS platform offering content management can use ML to increase engagement by showing users what they are most likely to enjoy. This real-world case proves how architecture and best practices combine to make your platform more interactive, data-driven, and user-focused.
8.6 Avoiding Common Pitfalls
- You should avoid mistakes that slow down your ML pipeline. These include creating one-time models instead of reusable pipelines, ignoring monitoring, or skipping data governance. For example, if you forget to track your model’s accuracy, it can make poor predictions later. By focusing on scalability, reusability, and monitoring from the start, you build a system that performs well over time. Careful planning helps your SaaS platform stay stable, trustworthy, and easy to expand as data grows.
8.7 Future Trends in SaaS ML Pipelines
- The future of ML pipelines in SaaS will focus on real-time data processing, self-service tools, federated learning, and model marketplaces. This means your system will analyze data instantly, allow non-engineers to build models, and reuse shared ML assets. There will also be a strong focus on fairness, explainability, and ethical AI. For example, future SaaS apps will explain how recommendations are made. These trends will make ML pipelines more transparent, powerful, and accessible for all users.
Conclusion: The Future of SaaS is Human with AI
- Building ML capabilities within a SaaS platform is not just about technology; it is about creating a living system that grows, learns, and collaborates. When you combine human creativity with AI precision, your SaaS solution becomes more than a product. It becomes an evolving ecosystem that constantly improves. A well-designed ML pipeline does not simply automate processes. It enhances decision-making, anticipates user needs, and transforms the customer experience.
- Think of AI not as a replacement but as your most capable teammate, one that never tires, learns constantly, and works with you to build better, faster, and smarter solutions. When you design your architecture with modularity, automation, observability, and scalability, you create a system that adapts as your users grow and your data expands. The collaboration between human insight and machine intelligence turns ordinary development into innovation and transforms every tenant challenge into an opportunity for progress.
- The future of SaaS innovation will not be defined by humans versus AI but by humans with AI, working together to create more meaningful, proactive, and intelligent products. The question is no longer whether you should integrate AI into your SaaS. It is how ready you are to embrace it as your most powerful partner. When you do, you are not just building software. You are creating the foundation for the next generation of intelligent and human-centered SaaS experiences.